第二章 设计审查
“确实如此,我们每个人背上都背着一个未经许可的核动力加速器,没什么大问题。”
—— Bill Murray在捉鬼敢死队(1984)中饰演Peter Venkman时所说
6.2.1 导言
在设计审查(design review)方面,计算机安全人员往往分为两大阵营。具有正式开发背景的人通常能够接受设计审查过程。这是很自然的,因为它与大多数正式的软件开发方法密切相关。设计审查过程似乎也比手工审查大型应用程序代码库更省事。
另一派是代码审计员,他们乐于发现最模糊、最复杂的漏洞。这群人倾向于将设计审查看作是一个象牙塔结构,只是妨碍了真正的工作。设计评审的形式化过程和对文档的关注成为深入研究代码的障碍。
事实是,设计审查(的价值)介于这两个阵营的观点之间,它对两者都有价值。设计审查是一个有用的工具,用于识别应用程序体系结构中的漏洞,并为实现审查(implementation review)确定组件的优先级。然而,它并没有取代实现审查;这只是整个审查过程的一部分。它使识别设计缺陷变得容易得多,并提供了对软件设计安全性的更全面的分析。在这种情况下,它可以使整个审查过程更有效,并确保你在投入的时间中获得最佳回报。
本章介绍了一些软件设计和设计漏洞的背景知识,并介绍了一个审查过程,以帮助你确定软件设计中的安全问题。
6.2.2 软件设计基础
在进入设计审查这个课题之前,我们先来回顾一下一些关于软件设计的基础。许多关于软件设计的概念在这章中与安全息息相关,特别是在威胁建模中(threat modeling)。以下几个小节介绍了学习设计安全所必要的关于软件设计的概念:
算法
软件工程归根结底可以认为是开发和实现算法的过程。从设计的角度来看,这个过程着重于开发关键的程序算法和数据结构,以及指定问题域逻辑。要了解系统设计的安全需求和漏洞潜力,你必须首先了解组成系统的核心算法。
问题域逻辑
问题域逻辑(Problem Domain Logic),或者业务逻辑(Business Logic) 提供了程序在处理数据时遵循的规则。 软件系统的设计必须包括软件执行的主要任务的规则和过程。软件设计的一个主要组成部分是与系统用户和资源相关的安全预期。例如,考虑具有以下规则的银行软件:
- 一个人可以从他/她的主要账户到任何其它合法账户中转账
- 一个人可以从他/她的市场账户(market account)到任何合法账户中转账。
- 一个人每个月只能从他/她的市场账户转一次账。
- 如果一个人在他/她的主要账户上的余额低于零,钱就会自动从他/她的市场账户转出,以抵消低于零的部分(如果这些钱足够的话)。
这个例子很简单,但是你可以看到,银行客户可能能够绕过市场帐户每月一次的转账限制。他们可以故意将自己的主要账户的资金取到余额低于0。因此,该系统的设计存在一个漏洞,银行客户可能会利用这个漏洞。
核心算法
通常,程序的性能要求决定了用于管理关键数据段的算法和数据结构的选择。有时可以从设计的角度评估这些算法的选择,并预测可能影响系统的安全漏洞。
例如,假如你知道一个程序将传入的一系列记录存储在支持基本顺序搜索的已排序链表中。基于这一知识可以预见的是,一个特别精心制作的庞大记录列表可能会导致程序花费大量时间在链表中进行搜索。对这样的关键算法的重复集中攻击很容易导致服务器功能的暂时甚至永久中断。
抽象与分解
软件设计的每个地方都不可避免地包含两个基本概念:抽象和分解。你可能已经熟悉了这些概念,但如果还不熟悉,下面的段落将提供一个简要的概述。
抽象(abstraction)是一种降低系统复杂性、使其更易于管理的方法。要做到抽象,只需要隔离最重要的元素并删除不必要的细节。抽象是人们感知周围世界的重要部分。他们解释了为什么你可以看到一个符号😊,就把它与一个微笑的脸联系起来。抽象允许你概括一个概念,例如面孔,以及其他相关的概念,例如微笑的面孔和皱眉的面孔。
在软件设计中,抽象是对应用程序将执行的流程进行建模的方式。它们使你能够建立相关系统、概念和流程的层次结构,从而隔离问题域逻辑和关键算法。实际上,设计过程只是构建一组抽象的方法,你可以通过开发过程实现它们。当一个软件必须解决一系列用户所关心的问题,或者它的实现必须分布在一个开发团队中时,这个过程变得特别重要。
分解(decopmesiton),或因式分解(factoring)是定义组成抽象的泛化(generalization)和分类的过程。分解可以在两个不同的方向运行。自顶向下的分解,即所谓的专门化,是将一个较大的系统分解成更小、更易于管理的部分的过程。自底向上的分解,称为泛化,涉及到识别许多组件中的相似性,并开发一个应用于所有组件的更高层次的抽象。
结构化软件分解的基本元素可能因语言的不同而不同。标准的自顶向下进展是应用程序、模块、类和函数(或方法)。有些语言可能不支持列表中的所有区别(例如,C语言不支持类);其他语言添加了更多的区别或使用略有不同的术语。 对于我们作设计审查的目的而言,这些差异并不重要,但是为了简单起见,本文主要讨论模块和函数。
信任关系
在第一章软件漏洞基础中,我们已经介绍了关于信任以及它是如何影响系统的全的。 本章对这一概念进行了扩展,指出多方之间的每一次通信都必须具有一定程度的信任。有一个术语叫信任关系(trust relationship)可以表述它。对于简单的通讯,两个群体都可以假设对另一方完全信任,也就是每个通讯群体都允许其他群体在参与通信时对暴露的功能拥有完全访问权限。然而,你更关心的时通信双方应该限制彼此信任的情况,这意味着各方只能访问到彼此功能的有限子集。通信的每一方施加的限制定义了他们之间的信任边界(trust boundary)。信任边界区分了信任共享的区域,称为信任域(trust domains)。如果你对这些概念有点迷惑,无需担心,下一节将提供一些示例。
软件设计需要考虑系统的信任域、边界和关系;信任模型(trust model)是表示这些概念的抽象,是应用程序安全政策的一个组件。此模型的影响在系统如何分解上很明显,因为信任边界也往往是模块边界。模型通常要求信任不是绝对的;相反,它支持被称为特权的不同程度的信任。一个典型的例子是标准的UNIX文件权限,用户可以为系统上的其他用户提供有限的文件访问权限。具体来说,用户可以指定是否允许其他用户读取、写入或执行文件(或这些权限的任何组合),从而将有限的信任扩展到系统的其他用户。
简单的信任边界
举一个简单的信任边界例子。考虑一个简单的单用户操作系统,比如Windows 98.为了使这和例子简单化,我们不考虑关于网络的部分。Win 98有简单的内存保护机制以及一些关于用户的概念,但它没有提供访问控制或者执行的措施。也就是说,如果用户可以登陆Win 98的系统,他就可以任意更改文件或者系统设定。因此,对于能够登陆上Win 98的交互性用户而言就不存在什么安全性。
你可以认为对于交互性的用户之间,(没有联网的)Win 98系统没有提供信任边界。然而你可以作这样的假设,即什么人可以物理访问这个系统。所以你可以说信任边界就在这种情况下定义了,即在能够拥有物理访问权限的用户和没有权限的用户。(这段有点拗口,用大白话说就是能摸到这台电脑的人和摸不到这台电脑的人之间有信任边界 —by 译者) 这样就只剩下一个由受信任用户组成的域和一个表示所有不受信任用户的隐式域。
让这个例子变得复杂一点,现在我们升级到多用户操作系统,比如Win XP专业版。现在我们就要考虑更多了。你可以想象两个拥有一般权限的用户不可以更改彼此的数据或者进程,当然,这个假设建立在你不是管理员用户(administrative user)的情况下。所以现在两个用户在系统中拥有了保密性以及完整性,这种保密性与完整系就构成了彼此的信任边界。当然由于管理员用户的存在我们也要假如其他的边界:非管理员用户无法影响到系统的完整性以及设置。这种边界是自然的,强加给用户之间的界限是必须的,毕竟如果任何用户都能影响到系统的状态,那就是单用户操作系统没什么不同了。下面是一个多用户操作系统的信任关系的图例:
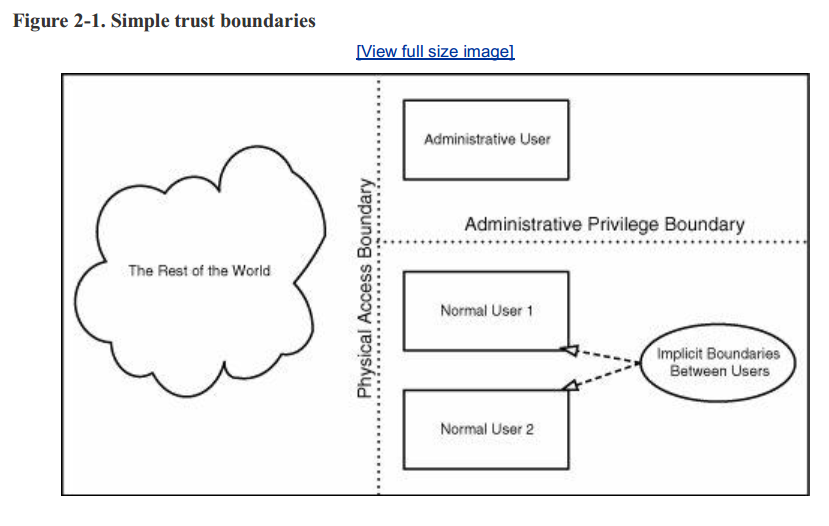
现在退一步考虑信任的本质。也就是说,每个系统最终都必须有一些绝对可信的权威。没有办法,因为必须有人对系统的状态负责。这就是为什么UNIX有一个root帐户,而Windows有一个管理员帐户。当然,你可以对这个级别的权限给与一系列的控件。例如,UNIX和Windows都有向不同用户授予不同程度的管理特权的方法。然而,一个简单的事实仍然是,在每个信任边界中,至少有一个可以承担责任的绝对权威(也就是至少有一个边界时由root 与非 root来划分的 ——by译者)。
复杂的信任关系
到目前为止,了解稍后需要处理的问题领域,你已经了解了相当简单的信任关系。然而,一些更详细的细节被忽略了。为了使讨论更实际一些,我们考虑连接到网络的同一个系统。
将系统连接到网络后,必须开始添加一系列区分。你可能需要为系统的本地用户和远程用户考虑单独的域,并且你可能需要 能够通过网络访问系统但不是“常规”用户的人提供域。 防火墙和网关进一步使这些区别复杂化,并引入了更多的区分。
很明显,定义和应用信任模型对任何软件设计都有巨大的影响。真正的工作在设计过程开始之前就开始了。可行性研究和需求收集阶段必须充分确定和定义用户的安全期望和目标环境的相关因素。生成的模型必须有足够的鲁棒性,以满足这些需求,但又不能复杂到难以实现和应用。这样,安全性就必须小心地平衡清楚性和准确性的需要。在本章后面的部分中,当研究威胁建模时,你将通过评估不同系统组件之间的边界和系统上不同实体的权限来考虑信任模型。
信任链
第一章介绍过了信任传递的观点,本质上说,信任传递就是如果组件A信任组件B,那么A就必须信任组件B所信任的所有组件。这个概念也可以称为信任链(chain of trust)关系。
信任链是一个完全可行的安全构造,也是许多系统的核心。考虑证书在到Web服务器的典型安全套接层协议(Secure Sockets Layer, SSL)连接中分发和验证的方式。你有一个本地签名数据库,用于标识你信任的提供者。然后,这些提供者可以向证书颁发机构(certificate authority CA)颁发证书,然后CA可以扩展到其他颁发机构。最后,托管站点的证书由这些机构之一签署。在建立SSL连接时,必须遵循从一个CA到另一个CA的信任链。 只有当到达可信数据库中的某个权限时,遍历才会成功。
现在,假设你想要模拟一个Web站点,以达到某种邪恶的目的。目前,不考虑域名系统(Domain Name System, DNS),因为它通常是一个容易的目标。相反,你所要做的就是找到一种方法来操作信任链中任何位置的证书数据库。这包括操作访客的客户端证书数据库、直接危害目标站点、或操作链中的任何CA数据库(包括根CA)。
为了确保重点明确,重复最后一部分更好一些。每个CA共享的信任的传递性意味着任何CA安全性弱的部分都允许攻击者利用然后成功地模拟任何站点。颁发实际证书的CA是否受到威胁并不重要,因为由有效的CA颁发的任何证书就足够了。这意味着任何SSL事务的完整性只取决于最弱的CA。不幸的是,此方法是用于建立主机标识的最佳方法。 有些系统只能通过使用可传递的信任链来实现。但是,作为一名审计人员,你需要仔细研究选择这种信任模型的影响,并确定信任链是否合适。你还需要遵循所有包含组件的信任关系,并确定任何组件的实际公开程度。你经常会发现,使用信任链的结果是造成复杂而微妙的信任关系,攻击者可以利用这些关系。
纵深防御
纵深防御(defense in depth)就是分层保护,这样系统如果一个地方有弱点那这个弱点就能被其他控制手段减轻。纵深防御的简单示例包括使用低权限用户运行服务和守护进程,以及将不同的功能隔离到不同的硬件上,更复杂的例子包括网络非军事区(network demilitarized zones, DMZs)、 chroot jails以及栈(stack)和堆(heap)保护。
当你为审查的组件划分优先级时,应当考虑分层防御。你可以能会将较低优先级分配给在低权限用户上运行的面向内部网的组件,该组件位于chroot jail中,并使用缓冲区保护进行编译。相反,你可能会为必须以root身份运行的面向因特网的组件分配更高级的优先级。这并不是说第一格组件时安全的,第二个不是。优先化威胁(prioritizing threat)将会在本章后面的“威胁建模”中详细讨论。
软件设计的原则
软件开发方法的数量似乎与软件开发人员的数量成正比。不同的方法适合不同的需求,项目的选择也因各种因素而异。幸运的是,每种方法都有一些公认的原则。准确性(accuracy)、清晰性(clarity)、松散耦合(loose coupling)和强内聚性(strong coherence)这四个核心原则适用于每个软件设计,是讨论设计如何影响安全性的良好起点。
准确性
准确性也就是一个设计抽象是怎样高效地来符合需求的。准确性包括了一个抽象对需求如何准确地建模,还包含了它们怎样被合理地实现。 当然,我们的目标是用最直接的实现方法提供最精确的模型。
在实践中,软件设计可能不会准确地转换为实现。在需求收集阶段的疏忽可能导致设计遗漏了重要的功能或强调了错误的关注点。设计过程中的失败可能会导致实现必然与设计产生巨大的差异,以满足实际的需求。即使流程中没有失败,预期和需求也会在实现阶段发生变化。所有这些问题都可能导致实现偏离预期的(和文档化的)设计。
软件设计及其实现之间的差异导致了设计抽象中弱点的出现。这些弱点是滋生各种漏洞的温床,包括安全漏洞。它们迫使开发人员在预期的设计之外做出假设,而未能传达这些假设通常会造成易受攻击的情况。注意设计没有充分定义的地方,或者对程序员有不合理的期望。
清晰性
软件设计可以为极其复杂且常常令人困惑的过程建模。为了达到清晰的目的,一个好的设计应该以一种合理的方式分解问题,并提供清晰、不证自明的抽象。结构的文档也应该很容易获得,并且参与实现过程的所有开发人员都应该很好地理解它。
不必要的复杂或文档记录不良的设计可能导致类似于不准确设计的漏洞。在这种情况下,抽象中的弱点会出现,因为对于精确的实现来说,对设计的理解太不到位了。你的审查应该识别出没有充分文档化或异常复杂的设计组件。你可以在整本书中看到这个问题的例子,特别是在第7章,“程序构建块”。
弱耦合性
耦合是指模块之间的通信级别以及模块之间相互公开内部接口的程度。松散耦合的模块通过定义良好的公共接口交换数据,这通常会导致更具适应性和可维护性的设计。相反,强耦合模块具有复杂的相互依赖关系,并公开其内部接口的重要元素。
强耦合模块通常彼此高度信任,很少为它们的通信执行数据验证。在这些通信中缺少定义良好的接口也使数据验证变得困难和容易出错。当其中一个组件可被攻击者控制时,这往往会导致安全缺陷。从安全的角度来看,您需要寻找任何跨信任边界的强模块间耦合。
强内聚性
内聚是指模块的内部一致性。这种一致性主要是模块的接口处理一组相关活动的程度。强内聚性鼓励模块只处理紧密相关的活动。保持强内聚的一个副作用是,它倾向于鼓励强内部耦合(单个模块的不同组件之间的耦合程度)。
当设计无法沿着信任边界分解模块时,可能会出现内聚相关的安全漏洞。由此产生的漏洞类似于强耦合问题,只不过它们发生在同一个模块中。这通常是系统在设计的早期阶段没有考虑安全性的结果。要特别注意在单个模块中处理多个信任域的设计。
基础的设计缺陷
现在你已经有了基本的理解,可以考虑一些基本设计概念如何影响安全性的示例。特别是,你需要了解误用这些概念会如何造成安全漏洞。在阅读下面的例子时,你会很快注意到它们往往是由一系列问题导致的。通常,一个错误是可解释的,并且很大程度上取决于审查者的观点。不幸的是,这是设计缺陷的一部分。它们通常在概念级别上影响系统,并且很难进行分类。相反,你需要关注问题的安全影响,而不是陷入分类中。
强耦合利用
本节将探索一个基本的设计缺陷,该缺陷是由于未能沿着信任边界正确分解应用程序而导致的。这些被称为粉碎漏洞(Shatter class of vulnerabilities),最初报告的独立研究的一部分由克里斯佩吉特进行。特定的攻击方式利用了Windows GUI应用程序编程接口(API)的某些属性。下面的讨论避免了许多细节,以突出设计的具体性质的粉碎漏洞。第十二章,“Windows II:进程间通信”提供了与这类漏洞相关的技术细节的更深入的讨论。
Windows程序使用消息系统(messaging system)来处理所有和GUI相关的事件,每个桌面都有一个消息队列,用于与之关联的所有应用程序。所以任意两个进程在同一个桌面上运行时都可以向彼此发送消息, 不管流程的用户上下文是什么。 这就会造成一个问题,即高权限的进程,例如服务进程,在普通用户的桌面上运行。
Windows API提供了 SetTimer()函数来为发送WM_TIMER消息安排时间。这个消息可以内含一个指向函数的指针,这个函数在当默认消息句柄(message handler)收到WM_TIMER调用。这就会造成一种情况,一个进程可以控制同一个桌面上运行的任何其他进程的函数的调用。 攻击者惟一关心的是如何为目标进程的执行提供代码。
Windows API包含了很多的消息用来更改窗口元素,通常,它们是用来设定文本框内容以及标签,更改剪贴板的内容。然而,攻击者可以利用这些消息从目标进程的地址空间出插入数据。将这些数据和WM_TIMER结合起来之后,攻击者可以在相同桌面的任何进程部署和运行任何代码。这就是一个权限升级漏洞,可以用于攻击在交互式桌面上运行的服务。
当这个漏洞发表后,微软更改了WM_TIMER消息的处理方法。核心问题就是,跨桌面的通信必须被视为潜在的攻击载体。 当你考虑到最初的消息传递设计受到单用户操作系统很大的影响时,这就更有意义了。在这种情况下,这样的设计就是准确的,清晰的,有强内聚性的。(即最初的消息传递机制就是为单用户操作系统设计的,这不影响到软件设计的三大原则,但扩展到多用户操作系统这就是一个漏洞了——by 译者)
此漏洞说明了为何难以将安全性添加到现有设计中。最初的Windows消息传递设计对于它的环境来说是合理的,但是引入了一个多用户操作系统改变了这种情况。消息传递队列现在在同一个桌面上拥有了强耦合以及不同的信任域。其结果是出现了新的漏洞类型,可以利用桌面作为公共接口。
信用传递的利用
一个很吸引人的Solaris安全问题显示了攻击者能够怎样在两个组件之间操纵它们的信任关系。一些版本的Solaris包括了使用root权限运行的RPC程序,automonted。这个程序允许root用户指定一个命令作为挂载操作的一部分运行,通常用于代表内核处理挂载和卸载。automonted程序不监听IP网络,只能通过三个受保护的环回传输访问,这意味着程序只接受来自root用户的命令,看起来还是很安全的。
另外一个程序,rpc.stated,在root权限下允许并且监听传输控制协议( Transmission Control Protocol, TCP)和用户数据报协议(User Datagram Protocol, UDP)。它被用作网络文件系统(NFS)协议支持的一部分,它的目的是监视NFS服务再它们关停时发送通知。通常的,NFS锁定守护进程询问rpc.stated来监视服务器。然而,注册rpc.stated要求客服端告诉它要联系哪个主机,以及要在该主机上调用哪个RPC程序号。
因此攻击者就可以联系一台机器的rpc.stated然后注册audomonted程序以接收崩溃通知。然后攻击者告诉rpc.stated被监视的NFS服务器崩溃了。于是roc.stated在本地机器上联系automonted守护进程(通过一些特殊的回送接口(look back interface))然后给它一个RPC消息。这个消息并不是automonted所期望的,但在一些修改之后,你就能对一个合法的audomonted请求进行解码。这个请求通过回送接口发自root,于是automonted就认为这个请求来自于内核部分,而结果是它执行了攻击者选择的命令。
在这个例子中,攻击rpc.stated的公共接口只在与automonted建立信任通信时有用。这个情况会发现因为所有在相同账户下运行的进程都是相互信任的,利用这种信任可以让远程攻击者向automonted进程发送命令。最终关于通信源的假设导致开发人员对automonted所接受的格式比较宽容。这个问题与模块之间的相互信任结合导致了远程root级别的漏洞。
故障处理
在软件设计中,正确的故障处理是清晰准确的可用性的重要组成部分。你当然只是希望应用程序能够正确地处理不正常的情况,并为用户提供解决问题的帮助。但是,故障条件可能会导致可用性和安全性出现冲突。有时,必须对应用程序的功能进行妥协,以实现安全性。
考虑一个网络程序,它检测客户端系统收到的数据中的故障或者故障条件。准确而清晰的可用性要求应用程序尝试恢复并继续运行。当无法恢复时,应用程序应该通过提供有关错误的详细信息来帮助用户诊断问题。
然而,面向安全的程序通常采用完全不同的方法,这可能涉及终止客户端会话和提供最低限度的必要反馈。之所以采用这种方法,是因为围绕安全理想而设计的程序假定故障条件是攻击者操纵程序输入或环境的结果。从这个角度来看,绕过问题并继续处理的尝试通常会正中攻击者的下怀。务实的防御反应是放弃正在发生的事情,在日志中发出血腥的尖叫,并终止处理。尽管这种反应似乎违反了一些设计原则,但这只是安全性需求的准确性取代了可用性需求的准确性和明确性的一种情况。
6.2.3 执行安全政策
第一章讨论了安全期望以及它时怎样影响一个系统的。现在你可以用这些概念来理解安全期望是怎样来执行安全政策的。 开发人员主要通过识别和加强信任边界来实现安全政策。作为一名审计人员,你需要分析这些边界的设计以及实现它们的实施的代码。为了更容易地处理安全策略的元素,执行被分成六个主要类型,在下面的部分中讨论。
身份验证
身份验证(authentication) 是程序确定用户声明的身份,然后检查该声明的有效性的过程。软件组件在发起通信时使用身份验证来建立对等方(客户端或服务器)的标识。一个典型的例子是要求网站的用户输入用户名和密码。正如你在前面关于SSL证书的讨论中所看到的,身份验证也不仅适用于人类。在此示例中,系统彼此进行身份验证,以在不可靠的接口上安全地运行。
常见的身份验证漏洞
一个值得注意的设计疏忽是在需要身份验证的情况下不进行身份验证。例如,一个Web应用程序提供了一个可能对内幕交易有用的敏感公司会计信息的摘要。将这些信息暴露给任意的互联网用户,而不要求进行某种身份验证,这将是一个设计缺陷。请注意,“缺乏身份验证”问题并不总是很明显,尤其是在大型应用程序中处理对等模块时。通常很难确定攻击者是否可以访问两个组件之间的内部接口。
通常,最佳实践是在设计中集中身份验证,特别是在Web应用程序中。有些Web应用程序要求通过主页访问的用户进行身份验证,但在后续页面中不强制进行身份验证。这种身份验证的缺乏意味着你不需要输入用户名或密码就可以与应用程序进行交互。相反,集中式身份验证通过验证受保护域中的每个Web请求来缓解这个问题
不可信的凭证
另一个常见的错误发生在向软件提供一些身份验证信息,但这些信息不值得信任。当在客户端执行身份验证时,这个问题经常发生,攻击者通过它可以完全控制连接的客户端。例如,SunRPC框架包括了AUTH_UNIX身份验证方案,这个方案是给予完全信任客户端系统的。客户端只是传递一条记录,该记录高屋服务器用户以及组的id是什么,而服务器只将他们作为事实接受。
UNIX系统以前包括一个RPC保护进程叫rexed(远程执行守护进程, remote execute daemon )。这个程序的目的是让远程用户像本地用户一样运行程序。如果你连接上了一个rexed系统然后告诉rexed程序运行/bin/sh命令,程序就会将shell像bin一样运行然后让你和它进行交互。这就是它的全部功能,除了不能作为root用户运行程序之外。特别地,在将shell作为bin运行之后,只需要几分钟就可以绕过这个限制。最近,一个远程root缺陷,在Solaris上默认安装的sadmind暴露了, 它将AUTH_UNIX身份验证作为代表客户机运行命令的充分验证。
注
关于sadmind的bug文档见 www.securityfocus.com/bid/2354/info
许多网络守护进程使用网络连接或包的源IP地址来建立对等点的身份确认。对于它自己来说,这个信息不足够可信并且容易收到篡改。UDP可以被很简单的方法欺骗,TCP连接也可以在很多情况下被欺骗或者拦截。UNIX提供了多个守护进程,它们遵循基于源地址的可信主机的概念。这些守护进程是rshd和rlogind,甚至sshd也可以通过配置来遵守这些信任关系。攻击者可以利用两个机器的信任关系,从这些受信任的机器中的高权限的端口通过初始化,欺骗攻击或者劫持一个TCP连接。
你可能在两个系统的程序化的身份认证中看到这种设计缺陷。如果程序使用这种身份认证机制,例如证书,设计层面的问题就会出现。首先,很多分布式的客户端/服务器应用只从一个方面认证身份:只通过客户端或者只通过服务器。攻击者经常可以利用这种身份验证的结构伪装成未经身份验证的用户,并对系统进行微妙的攻击。
使用加密方法自制的身份验证也是你可能常会遇到的问题。从一个概念性的角度来看,验证自己的身份看起来很简单。(此处省略一段难翻译的废话 —by译者)。但是,在从头创建身份验证协议时,有很大的错误空间。Thomas Lopatic在Firewall-1和FWN/1协议中发现了一个有趣的漏洞。每个对等点发送一个随机数R1和该随机数的哈希值以及共享密钥,Hash(R1+K).接收端库查看发送的随机数,计算哈希值,并将其与传输的值进行比较。问题是,你可以简单地将R1和Hash(R1+K)的值在服务器中重现,因为它们时使用相同的共享对称密钥生成的。
授权
授权是一个决定系统中的用户拥有什么样的权限在信任域中去做一些特定事务的过程。它作为权限控制(access control)策略的一部分与身份验证是一致的:身份验证告诉了这个用户是谁,授权决定了这个验证过的身份拥有做什么的权限。 有许多访问控制系统的正式设计,包括自由访问控制、强制访问控制和基于角色的访问控制。 此外,有几种技术可用于将访问控制集中到各种框架、操作系统和库中。由于不同访问控制方案的复杂性,最好从一般的角度来看待授权。
一般的授权漏洞
Web应用经常没有或者缺少足够的授权。你经常能发现只有一小部分网站做到了授权的检查。带有授权逻辑的页面通常是主菜单页面和主要子页面,但是实际的处理程序页面省略了授权检查。通常情况下,找到一种方法以相对低权限的用户登陆,然后能执行一些访问不属于你的账户信息以及做一些不属于你账户的行为这些为高权限用户所准备的操作。
不安全的授权
缺少授权显然是一个问题。你还可能遇到授权检查的逻辑不一致或者留下滥用空间的情况。例如,假如你有一个简单的消费跟踪系统,每个在公司的用户都有自己的账号。这个系统使用了公司的等级架构进行编写,所以它直到哪些员工是管理者,哪些是被管理者。它的主逻辑是像下面这样的数据驱动:
1 | Enter New Expensefor each employee you manage View/Approve expenses |
这个系统非常简单。假设初始化的公司员工等级架构是正确的,管理者可以审查与批准他们下属的费用。一般员工只能见到Enter New Expense的界面因为他们并不是管理者。
现在假设你在这样一种情况下运行这个程序,即一些员工都被一个人管理,但实际上他们要向另一个管理者报告日常事务。为了解决这个问题,你对这个程序做了这样的更改,即允许每个用户去选择其他用户作为自己的“虚拟的”管理员。一个用户的虚拟管理员(virtual manager)拥有查看与批准这个用户费用的权力,就像这个用户真正的管理员一样。这个解决方案第一眼看起来似乎还行,但它是有缺陷的。它可以允许用户将自己亲密的同事设置为虚拟管理员,包括他自己,这将导致费用的批准不受到任何限制。
这个简单的系统有一个明显的问题,可能看起来是人为设计的,但它是从实际应用中遇到的问题派生出来的。随着应用程序中的用户和组数量的增加以及系统复杂性的增加,设计人员很容易忽略授权逻辑中潜在的滥用可能性。
可追责性
可追责性(Accountability) 就是一个系统能够确认以及记录用户在系统中的所作所为。不可抵赖性是一个相关术语,实际上是可追责性的一个子集。 它指的是系统对某些用户操作进行日志记录的保证,这样用户就不能否认曾经执行过这些操作。 可追责性,身份验证和授权共同建立了完整的权限控制策略。不像身份验证和授权,可追责性并不形成一个信任边界或者防止漏洞的发生。但是,可追责性提供的数据对于减轻成功的入侵和进行法医式的分析(forensic analysis)是必不可少的。不幸的是,可追责行是应用程序设计安全中最容易忽视的部分之一。
常见的可追责性漏洞
最常见的可追责性漏洞就是一个系统对于登陆操作与敏感数据记录的失效。事实上,很多应用并不提供日志功能。当然,许多应用也不提供处理敏感数据时的日志记录。然而,管理者或者最终用户开发者需要决定什么样的日志记录是需要的。
另外一个主要的可追责性漏洞就是系统并没有正确地保护它的日志数据。当然,这个问题也可以划分为授权,保密性或者完整性漏洞。不管如何,任何系统在维护日志时需要保证它的安全。例如,下面展示了一个简单的文本日志,每行记录了时间戳以及登陆日志:
1 | 20051018133106 Logon Failure: Bob |
如果我在用户名上做手脚又会发生什么呢?比如说,一个叫"Bob\n20051018133106 Logon Success: Greg"的用户名看起来人畜无害,但是它确实可以用来做坏事。攻击者可以使用假的登录信息去掩盖有害的登陆,或者破坏日志使其变得不可读或者不可写。 这种破坏可能会造成拒绝服务的情况,或者打开通向其他漏洞的通道。它甚至可以在日志系统本身中提供可利用的路径。
除了这种日志的维护以外还有其他问题。如果攻击者能够读取日志呢?至少他们能够直到什么时候哪个用户会登入或者登出。从这个数据中,他们可能推断出一些登陆规律或者监视哪些用户会有忘记密码的习惯。这种信息看起来人畜无害,但它能为更大的攻击埋下伏笔。因此,未经授权的用户不能够向系统日志读取内容进行或者写入操作。
保密性
第一章给出了保密性的定义,即只有经过授权的一方才能够查看数据。这要求通过权限控制机制来实现,这种机制囊括了身份验证和授权。然而当通信在不安全的地段发生时,我们必须对安全引入新的考量(additional measure)。在这种情况下,加密技术通常用来满足保密性的需求。
加密(eccryption) 就是一个对信息编码的过程,如果第三方没有相关的知识(即解码方法 —by译者),那他就无法获得信息的确切内容。加密过程通常对一些数据有核心意义。核心数据只有通过授权之后才能访问其信息。
关于加密算法以及过程的主体并没有包含在在本书中,因为这其中的数学非常复杂,包含了一整个研究领域,要对它们有更深的了解,参考这本书:实用密码学 by Bruce Schneier and Niels Ferguson .(此处省略一些废话 —by译者)
加密算法
加密方法有很悠久的历史。然而我们关心的是可以用来有效保护交流数据的现代加密协议,本章我们关注两种加密的类别:对称型和反对称型。
对称加密(symmetric encryption) 或者共享密钥加密是一类所有授权方共享一份相同密钥的加密算法。 对称算法通常是最简单和最有效的加密算法。它们的主要缺点是,它们要求多方能够访问相同的共享机密。另一种方法是为每个通信关系生成和交换一个惟一的密钥,但是这种解决方案很快会导致无法维持的密钥管理情况。此外,非对称加密无法在任何共享密钥用户组中验证消息的发送方。
非对称加密(asymmetric encryption)(或公钥加密)是指每一方都有一组不同的密钥来访问相同加密数据的算法。这是通过为每一方使用一个公钥和私钥对来完成的。任何希望通信的各方都必须提前交换它们的公钥。然后,通过组合接收方的公钥和发送方的私钥对消息进行加密。生成的加密消息只能通过使用接收方的私钥解密。此外,非对称加密无法在任何共享密钥用户组中验证消息的发送方。
也就是说,非对称加密简化了密钥管理,并不要求暴露私有密钥,并且隐式地验证发送者的信息。然而, 非对称算法通常用于交换对称密钥,然后在通信会话期间使用该密钥。
分组密码
分组密码(block cipher)是一种对称加密算法, 它在固定大小的数据块上工作,并以多种模式运行。但是,在使用它们时,你应该知道一些注意事项。一个需要考虑的问题是,分组密码是独立加密每个组,还是使用前一个组的输出加密当前组。独立加密组的密码更容易受到密码分析攻击(cryptanalytic attacks ),应该尽可能避免。因此,分组密码链(cipher block chaining, CBC)模式密码是常规使用的唯一合适的固定组密码。它使用前面的数据组执行XOR操作,导致的性能开销可以忽略不计,并且比独立处理组的模式具有更高的安全性。
流密码
分组密码的最不便之处就在于它必须处理固定大小的数据组。任何一组数据如果比size大都必须分段,小于size的组必须进行填充。这个要求会在处理一些数据比如标准的TCP套接字(TCP socket)时为代码添加复杂度和难度。
幸运的是,分组密码可以允许在数据块大小任意时运行。在这种情况下,分组密码作为流密码(stream cipher)运行。 计数器(counter, CTR)模式密码是流密码的最佳选择。它的性能特征与CBC模式相当,但不需要填充或分段。
初始化向量
初始化向量(initialization vector)时用来启动分组密码的初始段。一个初始化向量需要进行加密时给出唯一的输出流,不管输入是否相同。初始化向量不需要保证私有(keep private),尽管它对于相同的密钥在每次新的加密过程中都必须不同。在有限的情况下,重复使用用初始化向量会导致使用CBC密码的信息泄漏;然而,它严重降低了其他块密码的安全性。一般来说,初始化向量的重复使用应该被认为是一个安全漏洞。
密钥交换算法
密钥交换协议的形式可以非常复杂,所以这一小节仅仅提供一些简单的知识点。首先,它的实现上应该使用标准密钥,比如RSA, Diffie-Hellman, o 或者El Gamal. 这些算法都已经被广泛验证,并且提供了最高等级的保障。
下一个问题是密钥交换是以一种安全的方式执行的,这意味着通信双方必须提供一些识别方法来防止中间人攻击。前面提到的所有密钥交换算法都提供了相关的签名算法,可用于验证连接的两端。这些算法要求双方已经交换了公钥,或者可以通过可信的源(如公钥基础设施( Public Key Infrastructure ,PKI)服务器)获得公钥。
加密过程的常见漏洞
现在你已经有了一些关于正确使用加密的背景知识,了解什么地方可能出错是很重要的。自定义加密是与机密性相关的漏洞的主要原因之一。加密是非常复杂的,需要广泛的知识和测试来正确设计和实现。因此,大多数开发人员应该将自己限制在已知的算法、协议和实现上,这些算法、协议和实现都经过了广泛的审查和测试。
不必要地存储敏感数据
通常情况下,没有任何实际原因就去设计维护敏感据,通常是因为对系统需求的误解。例如,验证密码不需要将密码存储在可检索的表单中。你可以安全地存储密码的哈希值并使用它进行比较。如果操作正确,此方法可以防止真正的密码被公开。(如果你不熟悉哈希值,请不要担心;它们将在本章后面的“哈希函数”中介绍。)
明文密码是不必要地存储数据的最典型的情况之一,但它远不是这个问题的唯一例子。有些应用程序设计不能正确地对敏感信息进行分类,或者只是莫名其妙地将其存储起来。真正的问题是,任何设计都需要正确地对其数据的敏感性进行分类,并且只在绝对需要时才存储敏感数据。
缺少必要的加密
通常,如果系统的设计目的是在可公开访问的存储、网络或不受保护的共享内存段之间传输明文信息,那么它就不能提供足够的保密性。例如,使用TELNET交换敏感信息几乎肯定是与机密性相关的设计漏洞,因为TELNET不加密其通信通道。
一般来说,任何有可能包含敏感信息的通信,在经过可能受到危害的公共网络时,都应该进行加密。在适当的情况下,应该在敏感信息存储在数据库或磁盘时对其进行加密。加密需要某种密钥管理解决方案,它通常可以绑定到用户提供的秘密,例如密码。在某些情况下,特别是在存储密码时,可以将敏感数据的散列值存储在实际敏感数据的位置。
不足的或者过时的加密
当然,使用设计不够强大的加密技术来提供所需的数据安全性也是有可能的。例如,56位的单一数字加密标准( Digital Encryption Standard,DES)加密可能是当前廉价的千兆赫计算机时代的一个糟糕的选择。请记住,攻击者可以记录加密的数据,如果这些数据足够有价值,他们可以在计算能力提高的后再等待解密成果。最终,他们将能够在Radio Shack公司获得一台128 q位的量子计算机,你的数据将属于他们(假设科学家在2030年前解决了老龄化问题,每个人都能长生不死)。
撇开玩笑不谈,重要的是要记住加密实现是会随着时间而变老的。计算机变得更快了,数学家发现算法中出现了新的漏洞,就像代码审核员在软件中发现的漏洞一样。一定要注意算法和密钥大小,它们不适合所保护的数据。当然,这是一个不断变化的目标,所以你所能做的最好的事情就是了解当前推荐的标准。国家标准和技术研究所(NIST;(www.nist.gov)在发布算法和密钥大小的普遍接受标准方面做得很好。
数据混淆与数据加密
一些应用程序甚至整个行业的安全标准似乎无法区分数据混淆(Obfuscation)和数据加密。简单地说,当攻击者能够访问恢复编码的敏感数据所需的所有信息时,数据就会变得混淆。这种情况通常发生在编码数据的方法没有包含唯一密钥,或者密钥与数据存储在同一个信任域中的情况下。不包含唯一密钥的编码方法的两个常见示例是ROT13文本编码和简单的XOR机制。
将密钥存储在与数据相同的上下文中的问题更令人困惑,但并不一定就不那么常见。例如,许多支付处理应用程序在其数据库中存储加密的敏感帐户持有人信息,但所有处理应用程序都需要密钥。这一要求意味着,窃取备份媒介可能不会向攻击者提供帐户数据,但破坏任何支付服务器都可以让他们获得密钥和加密的数据。当然,你可以添加另一个密钥来保护第一个密钥,但是所有处理应用程序仍然需要访问。你可以按自己的意愿分层存储任意多的密钥,但最终,这只是一种混淆技术,因为每个处理应用程序都需要解密敏感数据。
注
支付卡行业( Payment Card Industry, PCI)1.0数据安全要求是整个行业标准的一部分,以帮助确保安全处理支付卡数据和交易。这些需求是业界的一个前瞻性举措,其中许多与最佳安全实践保持一致。然而,该标准包含的要求恰恰产生了本章所述的机密性问题。特别是,要求允许将加密的数据和密钥存储在相同的上下文中,只要密钥是由驻留在相同上下文中的另一个密钥加密的。
最后一点是,在过去的几年中,通过模糊(或混淆)实现的安全性已经赢得了不好的名声。就其本身而言,它还不足以保护数据不受攻击者的攻击;它只是没有提供足够强的保密性。然而,在实践中,混淆可能是任何安全策略的一个有价值的组成部分,因为它可以阻止偶然的窥探者,并且通常可以放缓专业的攻击者的脚步。
完整性
第一章将完整系定义为只有经过授权的用户能够修改数据的期望。这个需求像保密性一样也是通过权限管理机制来实现的。 但是,当通过不安全的通道进行通信时,必须采取其他措施。在这些情况下,将使用下面讨论的某些加密方法来确保数据完整性。
哈希函数
加密数据的完整性时通过各种方法来实现的,尽管哈希函数是大多数方法的基础。哈希函数,或者消息摘要函数( message digest function)接受可变长度的输入并生成固定大小的输出。哈希函数的有效性主要通过三个要求来衡量。首先它必须是不可逆的,也就是知道输出,不能确定输入。这个要求称为无预映像(no pre-image)要求。第二个要求是函数没有预映像,也就是给定输入和输出,不能生成具有相同输出的输入。最后也是最严格的,哈希函数必须相对无中途,也就是不可以由不同的输入生成相同的输出。
哈希函数提供了大多数编程完整性保护的基础。它们可用于将任意一组数据与惟一的、固定大小的值相关联。这种关联可以用来避免保留敏感数据,并大大减少验证数据所需的存储空间。哈希函数最简单的形式是循环冗余校验(cyclic redundancy check,CRC)例程。它们速度快、效率高,并提供了一定程度的保护,防止无意的数据修改。然而,CRC函数对有意修改无效,这使得它们不能用于安全目的。一些常用的CRC函数包括CRC-16、CRC-32和Adler-32。
CRC函数的下一步是加密哈希函数。它们的计算量要大得多,但它们对有意和无意的修改提供了高度的保护。常用的哈希函数包括SHA-1、SHA-256和MD5。(有关MD5的问题将在本章后面的“诱饵-开关攻击”中详细讨论。)
盐值
盐值(salt values)(这个真不知道怎么翻译,那就借用大逼乎的盐值吧 —by 译者)和初始化向量几乎非常相近。’salt‘表示信息中加入了一些随机数以至于两条信息不会生成相同的哈希值。相比于初始化向量,盐值必须不能从信息之间复制。除了哈希值之外,还必须存储一个盐值一遍能够正确地重构柴窑以进行比较。 然而和初始化向量不同的是, 盐值在大多数情况下应该得到保护。
盐值最常用来防止基于预计算的对消息摘要的攻击。大多数密码存储方法都用一个固定的哈希值来防止这个问题。再预计算攻击中,攻击者构建一个包含所有可能摘要值得字典,以便能够确定原始数据值。这种方法只适用于输入值很小的范围,比如密码,然而它在这种范围内可以非常有效。
考虑一个应用于任意密码的32位随机值。盐值将密码预计算字典的大小增加了40亿倍(232)。由此产生的预计算字典对于密码的一小部分来说可能太大了。由Philippe Oechslin开发的Rainbow表是一个真实的例子,它说明了缺少盐值会使密码哈希容易受到预计算攻击。Rainbow表可用于在几秒钟内破解大多数密码哈希,但这种技术只有在散列不包含盐值的情况下才有效。你可以在Project RainbowCrack网站上找到更多关于彩虹表的信息:http://www.antsight.com/zsl/rainbowcrack/。
发起者验证
哈希函数提供了验证消息内容的方法,但是它们不能验证消息源。验证消息的来源需要在哈希操作中加入某种形式的私钥;这种类型的函数称为基于哈希的消息验证码( hash-based message authentication code HMAC)函数。消息验证码是一个函数,返回从密钥和可变长度消息计算得到的固定长度值。
基于哈希的消息验证码是一种使用共享秘密验证消息内容和发送方的相对快速的方法。不幸的是,基于哈希的消息验证码与任何共享密钥系统都有相同的弱点:攻击者可以通过仅泄漏一方的密钥来模拟对话中的任何一方。
加密签名
加密签名(Cryptographic Signatures)是一种将消息摘要与特定公钥相关联的方法,它使用发送方的公钥和私钥对消息摘要进行加密。 任何收接收者可以使用发送者的公钥对消息摘要进行解码然后讲结果值与计算后得到的消息摘要做比较。这种比较为消息来源者必须对密钥具有访问权提供了保证。
完整性的常见漏洞
完整性漏洞和保密性漏洞很相似,大多数完整性漏洞事实上可以通过对保密性的严格要求来预防。接下来几小节讨论在一些特定的情况下与完整性有关的设计漏洞。
诱骗攻击(Bait-and-Switch Attacks)
(注:Bait-and-Switch为美国俚语,bait即引诱别人的鱼饵鱼饵,switch即在别人上套之前用别的东西替代,这里翻译为诱骗 —By译者)
常用的哈希函数必须接受大量的公共审查。然而,随着时间的推移,出现的弱点往往可以被攻击者利用。诱骗攻击就是对几种首先被发现的老以前哈希函数的弱点之一实行打击的。这种攻击利用了哈希函数在一些特定范围的输入中倾向于产生冲突的弱点。攻击者可以利用这种弱点用两个不同的输入产生相同的值。
例如,假设你有一个处理钱款转账请求的银行应用程序。这个程序收取请求,如果请求是合法的,那么就进行转账步骤。如果哈希函数是有缺陷的,攻击者就可以生成两笔拥有相同信息摘要的转账。然后攻击者可以用最低余额开设帐户,并获得较小的转账批准。然后,他们会向下一个系统提交更大的请求,并在其他人知道之前结清账户。
诱骗攻击最近是一个流行的主题因为SHA-1和 MD5已经开始被发现出了一些弱点。MD5的冲突漏洞最早在1996年就被发现,但直到2004年四个人(名字不翻译了 —by译者)发表了一篇成功导致MD5冲突漏洞算法的文章。2005年三月,三个研究者又紧随其后, 他们成功地生成了一对具有不同公钥的X.509证书,这是SSL中使用的证书格式。 最近,Vlastimil Klima在2006年3月发布了一种算法,能够在极短的时间内找到MD5碰撞。
SHA算法家族也受到密切关注。若干对SHA-0的潜在攻击已经确定了;但在SHA-0很快就被SHA-1所取代,并且没有出现任何明显的漏洞。SHA-0攻击研究为识别SHA-1算法的漏洞提供了基础,尽管在撰写本文时,还没有任何一方成功地生成SHA-1冲突。然而,这些问题已经导致了几个主要的标准机构(如美国)开始逐步淘汰SHA-1,支持SHA-256(也称为SHA-2)。
当然,寻找随机冲突比寻找可以实施诱骗攻击的碰撞要困难得多。然而,就其本质而言,选择加密算法时应考虑到其安全性将远远超出适用系统的生命周期。这种观点解释了近年来哈希算法的转变,哈希算法之前被认为是相对安全的。这种变化的影响甚至可以在密码哈希应用程序中看到,这些应用程序不直接受到基于冲突的攻击,但也被升级为更强大的哈希函数。
实用性
第1章实用性定义为在需要时使用资源的能力。这种实用性预期通常与可靠性有关,而与安全性无关。但是,在许多情况下,系统的可用性应该被视为安全需求。
常见的实用性漏洞
与实用性设计失败相关的一般漏洞只有一种类型——拒绝服务(denial-of-service, DoS)漏洞。当攻击者可以通过执行一些未预期的操作使系统不可用时,就会出现DoS漏洞。
DoS攻击的影响很大程度上取决于它发生的环境。一个关键的系统可能包含对持续实用性的期望,而进程中断往往是不可接受的业务风险。核心业务系统(如集中式身份验证系统或旗舰网站)通常都是这种情况。在这两种情况下,成功的DoS攻击可能直接导致收入的重大损失,因为企业在没有系统的情况下无法正常运作。实用性的缺乏还会带来安全风险,因为停机会迫使以不太安全的方式处理需求。例如,考虑一个销售点(point-of-sale,PoS)系统,该系统通过一个中央调节服务器处理所有信用卡交易。当调节服务器不可用时,PoS系统必须在本地暂时存储所有事务,并在稍后的时间执行它们。攻击者在PoS系统和协调服务器之间诱导DoS的原因可能有很多。DoS条件可能允许攻击者用偷来的或无效的信用卡购物,也可能在不太安全的PoS系统上暴露持卡人信息。
6.2.4 威胁建模
现在,你应该对设计如何影响软件系统的安全性有了很好的了解了。系统定义了向用户提供的功能,但受安全策略和信任模型的约束。下一步是将你的注意力转移到开发一个将这些知识应用到您要审查的应用程序的过程上。理想情况下,你需要能够识别系统设计中的缺陷,并根据最安全关键的模块对实现审查进行优先级排序。幸运的是,一种称为威胁建模(threat modeling)的形式化方法正是为此目的而存在的。
在这一节,你将会使用具体有5个步骤阶段的威胁建模方式:
- 信息收集
- 应用架构建模
- 威胁识别
- 对寻找的结果进行文档记录
- 确定实施审查的优先次序
此过程是在开发的设计(或重构)阶段最有效的应用,并在稍后的开发阶段进行修改时更新。但是,它可以在SDLC的稍后阶段完全集成。它还可以在开发后应用,以评估应用程序的潜在风险。你选择的阶段取决于自己的需求,但是请记住,设计审查只是完整应用程序评审的一个组成部分。因此,请确保考虑到执行最终系统的实现和操作审查的需求。
这种威胁建模方法有助于建立一个框架,将你已经学过的许多概念联系起来。这个过程也可以作为本书其余部分中应用许多概念的路线图。但是,你应该学会调整,根据需要更改这些技术,以适应不同的情况。请记住,过程和方法可以成为好的仆人,但不是好的主人。
信息收集
威胁建模的第一步就是集中应用程序中的所有信息。在这个阶段你应该不要把太多精力花在只和安全相关的信息因为在这个阶段你还不知道什么信息是和安全相关的。相反,你应该为最终的实现阶段审查提供为了理解整个程序尽可能多的信息。下面是在完成这个步骤后你需要确定的信息:
- 资产。资产包括了在这个系统中所有对于攻击者有价值的东西。它们可能是在应用中包含的数据或者附加的数据库,例如包含用户账号和尼玛的数据表。资产也可以认定为应用程序的某些部分,例如在目标系统中运行任意代码的能力。
- 进入点。进入点包括任何攻击者可以连接上系统的路径。它们包括主动暴露的结构,比如监听接口,远程过程调录(Remote Procedure Call ,RPC)终点,上传的文件或者任何客户端发起的活动。
- 外部信任等级。外部新人等级也就是一个外部实体所拥有的权限,就像在本章前面“信任关系”所讨论的那样。一个复杂的系统可能会对不同的外部实体有好几个外部信任等级,但一个简单的应用程序应该只会考虑局部和远程访问权限的问题。
- 主要的组件。主要的组件顶一个这个应用设计的结构。组件可以是在程序内部的,或者它们可以是外部的模块依赖。威胁建模过程包括了对这些组件进行分解然后确定只和安全相关部分的过程。
- 使用场景。使用场景涵盖了系统的所有潜在应用程序。它们包括了授权后的和未授权的使用场景。
开发者访谈
在很多情况下,你可以节省很多时间,直接和开发人员交流。所以,如果你有机会接触到开发人员,一定要利用这种机会。当然,这个选项可能不可用。例如,独立的漏洞研究人员很少能够访问到应用程序的开发人员。
当你接触系统开发人员时,您应该记住以下几点。首先,你可以批评他们投入了大量时间和精力的工作。要明确表示,你的目标是帮助提高应用程序的安全性,并避免在你的方法中出现任何主观判断或屈尊俯就的情况。在进行了适当的对话之后,你仍然需要验证针对应用程序实现获得的任何信息。毕竟,开发人员可能有自己的误解,这可能是导致某些漏洞的一个因素。
开发者文档
一个文档良好的应用程序可以使审查过程更快更彻底;然而,这种便利有一个主要问题。对于现有实现的任何设计文档,都应该始终保持谨慎。这种谨慎的原因通常不是欺骗或不称职的开发人员;只是在实现过程中发生了太多的变化,以至于结果无法完全符合规范。
许多因素导致了规范和实现之间的不一致性。由于开发人员的更替和随着时间的推移而产生的轻微疏忽,非常大的应用程序常常会与它们的规范产生巨大的偏差。实现也可以不同,因为两个人很少对规范有完全相同的解释。底线是,你应该期望根据实际实现验证你从设计中确定的所有内容。
请记住这一点,你仍然需要知道如何从你获得的文档中提取所有内容。一般来说,你希望得到你可以得到的任何东西,包括设计(图、协议规范、API文档等等)、部署(安装指南、发布说明、补充配置信息等等)和最终用户文档。在二进制(和一些源代码)评审中,你只能获得最终用户文档,但不要低估它的价值。此文档是“面向客户”的文献,因此它一般是相当准确的,并且可以提供以流程为中心的视图,从而使系统更易于理解。
标准文档
了解这些协议和文件格式是如何构造的对于了解应用程序应该如何工作以及可能存在的缺陷是必要的。因此,获取由研究人员和作者创建的任何已发布的标准和相关文档是一个好主意。通常,与因特网相关的标准文档可以作为评论请求(Request for Comments . RFCs)(可在www.ietf.org/rfc/上获得)。相同标准的开源实现在澄清你在研究目标应用程序使用的技术时可能遇到的歧义方面特别有用。
源码概要分析
当你试图收集关于应用程序的信息时,看看源代码的非常有用。在这个阶段,你不需要做得太深入,但是拥有源代码可以加快许多初始建模过程。源代码可用于初始验证文档,你可以从代码中的类和模块层次结构确定应用程序的一般结构。当源看起来不是分层布局的时候,你可以查看应用程序启动,以确定初始化时主要组件是如何区分的。你还可以通过浏览代码来识别入口点,以查找常见的函数和对象,如listen()或ADODB。
系统概要分析
系统概要分析需要访问应用程序的功能,这使你有机会验证文档审查并识别文档遗漏的元素。从文档中严格执行的威胁模型需要跳过此步骤,并在实现检查期间完全验证模型。
你可以使用各种方法来分析应用程序。以下是一些常用的技巧:
- 文件系统布局。查看程序的文件系统不觉然后记录任何重要信息。这些信息包括了确定权限结构,监听所有可运行模块,异界确定任何相关数据文件。
- 代码再利用。查看所有可能来自其它库或者包的应用程序组件,例如嵌入的Web服务器或者加密库。这些组件可能自己带有可以攻击的点,所以需要额外的审查。
- 输入和输出。列出所有模块函数的输入和输出。 仔细查看用于建立或管理外部连接或RPC接口的任何库
- 沙盒测试。在沙盒中运行程序,然后识别它所触及的每个对象和它所执行的每个活动。使用探测器和应用程序代理来记录任何网络流量并隔离通信。在Windows环境,Filemon、Regmon、WinObj和来自(www.sysinternals.com)Process Explorer中使用程序有助于这个步骤进行。
- 扫描。 在任何监听端口、RPC接口或类似的外部接口上探测应用程序。尝试抓取横幅以验证正在使用的协议并确定任何身份验证需求。对于HTTP应用程序,尝试搜索链接并标识尽可能多的唯一入口点。
应用程序架构建模
了解了一些背景信息之后,你需要开始研究应用程序体系结构。这个阶段包括熟悉软件的结构,以及哪些组件会影响软件的整体安全性。这些步骤有助于确定设计关注点,并让你知道在实现审查期间应该将精力集中在哪里。你可以通过查看应用程序模型的现有文档并根据需要开发新模型来构建这些知识。在软件开发过程中,对软件的各个部分进行一定程度的建模;唯一的区别是这些模型是否被正式记录过。因此,你需要了解常用的建模类型以及如何开发自己的模型。
统一标记语言
统一标记语言(Unified Markup Language, UML) 是由对象管理小组(OMG;(www.omg.org/uml/)来描述应用程序在相当高的层次上如何运行的许多不同方面。它包括描述信息流、组件之间的交互、应用程序可能处于的不同状态等的图表。在这个阶段中特别有趣的是类图、组件图和用例。下面的列表简要地描述了这些类型的图,以便你对它们试图表达的内容有一个大致的了解。如果你不熟悉UML,那么强烈建议你从关于这个主题的无数书籍中挑选一本。由于UML的复杂性,深入地解释它远远超出了本章的范围。
注
UML已经经过了几个版本迭代,现在大家都用UML2.0.
类图。类图是用于建模面向对象(OO)解决方案的UML图。每个对象类都由一个包含类中的方法和属性的矩形表示。然后,对象之间的关系由类之间的线表示。有箭头的线表示了继承关系,两端有数字没有箭头的线表示基数关系。
当你试图理解复杂模块中的关系时,类图会很有帮助。它们基本上阐明了应用程序如何建模以及类之间如何交互。然而,实际上,你不会经常遇到这些问题,除非您正在执行内部代码检查。通过分析OO解决方案,可以大致构造类图。尽管这样做似乎有点浪费时间,但是当你稍后需要回来审查相同的软件时,或者当你执行初始的高级审查,然后将各种代码审计任务交给团队的其他成员时,它们会很有用。
组件图。组件图将解决方案划分为其组成的组件,连接符号用来它们之间的交互方式。组件被定义为一个不透明的子系统,它为解决方案提供一个独立的功能。组件的示例包括数据库、某种描述的解析器、排序系统等等。与类图相比,组件图提供的系统视图不太复杂,因为组件通常表示一个完整的自包含子系统,通常由许多类和模块实现。
组件图公开接口用突出的圆圈表示,使用其他组件的接口用空半圆表示。组件通过这些接口公开或通过关联线的方式绑定在一起,这表明两个组件是内在相关的,不依赖于公开的接口。组件图还允许通过实现将两个组件连接在一起。实现仅仅意味着一个组件所需要的功能是另一个组件的接口所公开的功能的子集。实现用虚线表示。
在审计过程中,组件图对于定义系统的高级视图及其组件间关系很有价值。当你试图开发威胁模型的初始上下文时,它尤其有用,因为它消除了系统的许多复杂性,并允许你关注全局。
用例。用例可能是UML标准中最模糊的组件。对于用例应该是什么样子或者包括什么,没有严格的要求。它可以用文本或图形表示,开发人员可以选择自己喜欢的方式。从根本上说,用例旨在描述应用程序应该如何使用,因此一组好的用例可以派上用场。毕竟,当你知道应用程序应该做什么时,解决它不应该做什么就比较容易了。在评审用例时,要注意开发人员对系统行为的任何假设。
数据流图
许多绘图工具可以帮助理解系统,但是数据流图(data flow diagram, DFD)是最有效的安全工具之一。这些图用于映射数据如何在系统中移动,并标识任何受影响的元素。如果处理得当,DFD建模过程不仅要考虑直接向外部源公开的应用程序功能,还要考虑间接公开的功能。这个建模过程还考虑了系统设计中的缓和因素,例如加强信任边界的附加安全措施。图2-2显示了DFD的5个主要元素,总结如下:
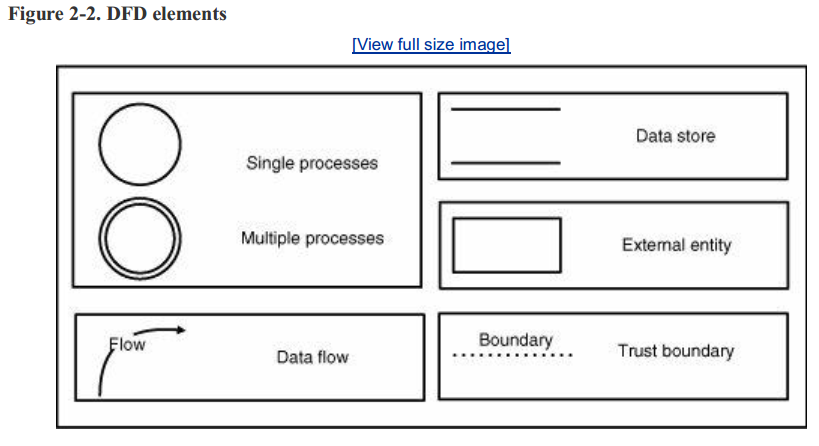
- 流程。流程是不透明的逻辑组件,具有定义良好的输入和输出需求。它们用一个圆圈表示,相关的进程组用一个带有双边框的圆圈表示。可以在每个流程的附加dfd中进一步分解多个流程组。尽管流程不是典型的资产,但它们在某些上下文中可能是资产。
- 数据存储。数据存储是系统使用的数据资源。例如文件和数据库。它们用由开放的矩形框表示。 通常任何在系统中的数据存储都属于资产。
- 外部实体。前面“信息收集”中描述的这些元素是“参与者”和远程系统,它们通过系统的入口点与系统通信。它们用封闭的矩形表示。识别外部实体可以帮助您快速隔离系统入口点,并确定哪些资产可以从外部访问。外部实体也可能表示需要保护的资产,例如远程服务器。
- 数据流。数据流用箭头表示。它表示数据是从哪来到哪去。这些元素在发现哪些用户支撑的数据能够到达哪些特定组件很有帮助,因此这样你就可以在实现审查阶段对它们进行定位。
- 信任边界。信任边界就是在系统或者在两个系统之间的边界。它们用两个组件之间的虚线表示。
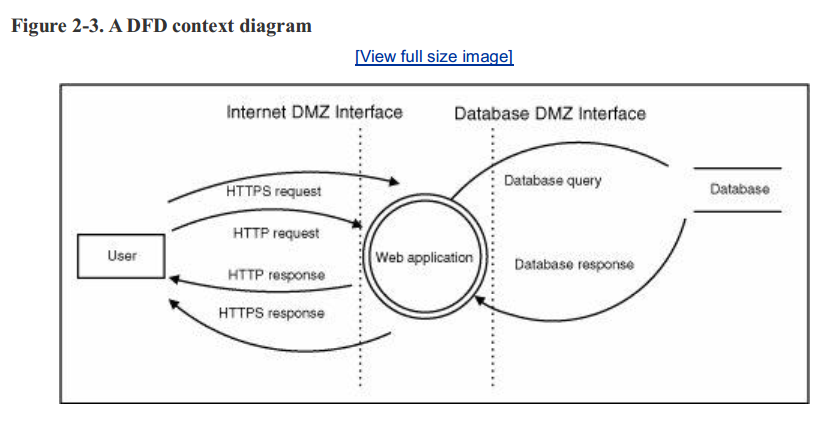
图2-3演示了如何使用DFD元素建模系统。它表示基本Web应用程序的简化模型,允许用户登录并访问存储在数据库中的资源。当然,DFD在应用程序的不同级别上看起来是不同的。封装大型系统的简单、高级DFD称为上下文关系图。Web站点示例是一个上下文图,因为它表示封装了一个复杂系统的高级抽象。
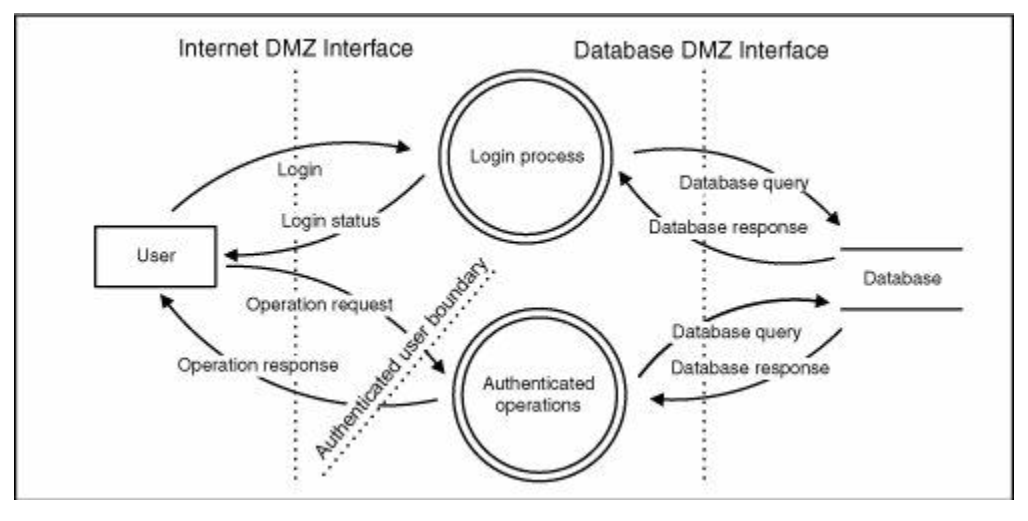
然而,你的分析通常需要您进一步分解系统。每个连续的分解级别都用数字标记,从零开始。0级图标识了主要的应用程序子系统。这个Web应用程序中的主要子系统由用户的身份验证状态来区分。这种区别在图2-4的0级图中表示出来。
根据系统的复杂性,你可能需要继续分解。图2-5是Web应用程序登录过程的一级图。通常,在建模复杂的子系统时,你只用在0级图之上进行。然而,这个1级图也为使用dfd隔离设计漏洞提供了一个有用的起点。
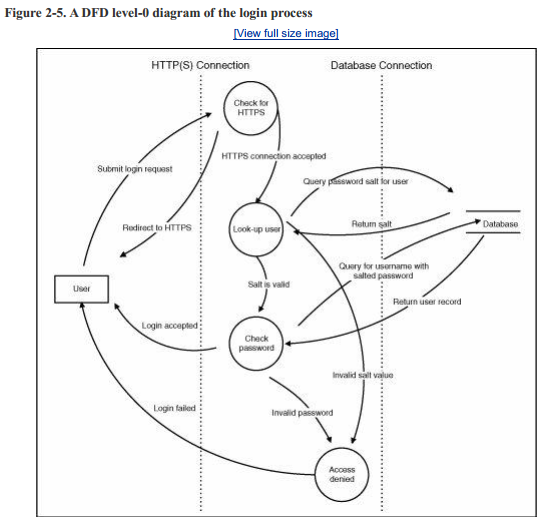
在准备实现审查时,你可以使用这些图来建模应用程序行为并隔离组件。例如,图2-6显示登录过程略有更改。你能看到漏洞在哪吗?登录过程处理无效登录的方式已经改变,因此它现在直接将每个阶段的结果返回给客户端。这个修改后的进程很容易受到攻击,因为攻击者可以在不成功登录的情况下识别有效的用户名,这在尝试对身份验证系统进行蛮力攻击时非常有用。
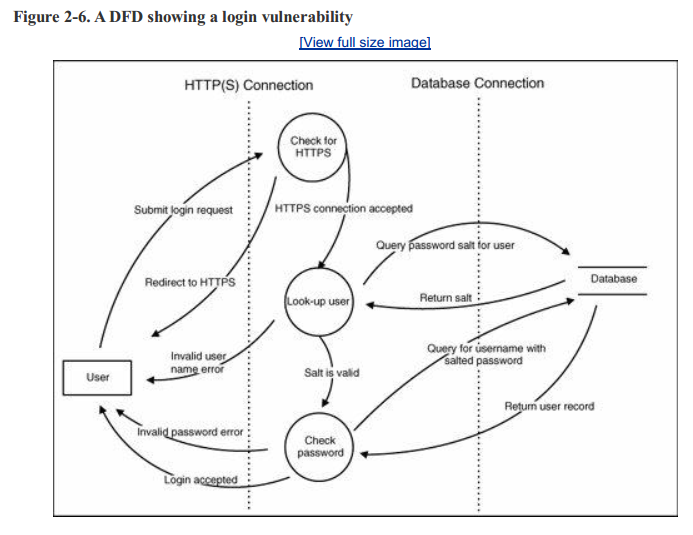
通过绘制这个系统的图表,你可以更容易地识别它的安全组件。在本例中,它帮助你以系统身份验证的方式隔离漏洞。当然,登录示例仍然相当简单;更复杂的系统可能具有多个复杂层,必须封装在多个dfd中。你可能不希望对所有这些层进行建模,但是你应该分解不同的组件,直到达到与安全相关的考虑事项隔离的程度。幸运的是,有一些工具可以帮助这个过程。绘制图表的应用程序,如Microsoft Visio是有用的,而Microsoft威胁建模工具在此过程中尤其有用。
威胁识别
威胁识别是基于你对系统的了解来确定应用程序的安全暴露的过程。此阶段构建于您在前一阶段所做的工作之上,通过应用您的模型和对系统的理解来确定系统对外部实体的脆弱性。在这个阶段,你将使用一个称为攻击树(或威胁树)的新建模工具,它提供了一种标准化的方法来识别和记录系统中潜在的攻击向量。
画威胁树
攻击树的结构非常简单。它由一个根节点(描述攻击者的目标)和一系列子节点(指示实现目标的方法)组成。树的每一层都将这些步骤分解为更详细的内容,直到你对攻击者如何利用系统有了一个实际的了解。使用上一节中的简单Web应用程序示例,假设它用于存储个人信息。图2-7显示了此应用程序的高级攻击树。
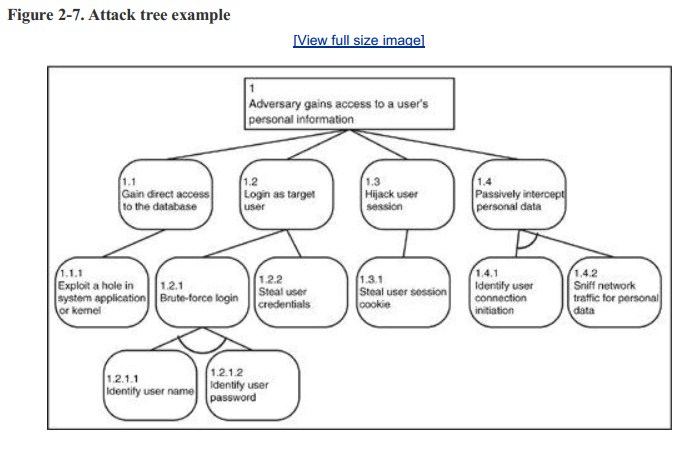
如你所见,根节点位于顶部,下面有几个子节点。每个子节点都声明了一种攻击方法,可用于实现根节点中指定的目标。这个过程根据需要进一步分解为最终定义攻击的子节点。查看这个图,你应该开始注意攻击树和dfd之间的相似性。毕竟,攻击树不是在真空中开发的。最好的创建方法是遍历DFD并使用攻击树来记录特定的关注点。作为一个例子,请注意导致子节点1.2.1的分支如何遵循前面在分析有缺陷的登录过程的DFD时使用的相同推理模式。
与dfd一样,你希望只沿着与安全相关的路径分解攻击树。你需要使用你的判断并确定哪些路径构成合理的攻击向量,哪些向量不太可能。但是,在进入这个主题之前,请继续下一节以获得对攻击树结构的更详细的描述。
节点类型
你可能已经注意到在连接每个节点及其子节点的行中有一些奇怪的标记(例如节点1.2.1.1和1.2.1.2)。这些节点连接器之间的弧表示子节点是与(AND)节点,这意味着必须满足子节点的两个条件才能继续计算向量。没有弧的节点只是一个或(OR)节点,这意味着任何一个分支都可以在没有任何附加条件的情况下被遍历。参考图2-7,查看节点1.2.1中的蛮力登录。要遍历此节点,必须满足两个子节点中的以下条件:
- 验证用户名
- 验证密码
任何一个步骤都不能掠过。因此,节点1.2.1是一个AND节点。
相反的是,OR节点描述了一个目标可以通过任何一个子节点达到的情况。所以只有满足单个节点的条件才能继续计算子节点。 回到图2-7,看一下节点1.2的“作为目标用户登录”。这个目标可以通过两个方法之一实现:
- 强制登陆
- 偷取用户证书
作为用户登陆,只需要实现其中之一就可以。因此它们是OR节点。
文本表示
你可以用文本和图形表示攻击树。文本版本传递的信息与图形版本相同,但有时不太容易可视化(尽管它们更紧凑)。下面的例子展示了如何用文本格式表示图2-7中的攻击树:
1 | 1. 对方获得访问用户个人信息的权限 |
如你所见,所有相同的信息都存在。首先,根节点目标被声明为攻击树的标题,它的直接后代在标题下面进行编号和缩进。每个新层都再次缩进,并以相同的方式在父节点下面编号。AND和或关键字用于指示节点是AND还是节点。
威胁减轻
攻击树的部分价值在于它允许你跟踪潜在的威胁。但是,如果无法确定如何减轻威胁,跟踪威胁就不是特别有用。幸运的是,攻击树包括一种特殊类型的节点来解决这个问题:循环节点。图2-8显示了一个带有适当缓解因素的示例攻击树。
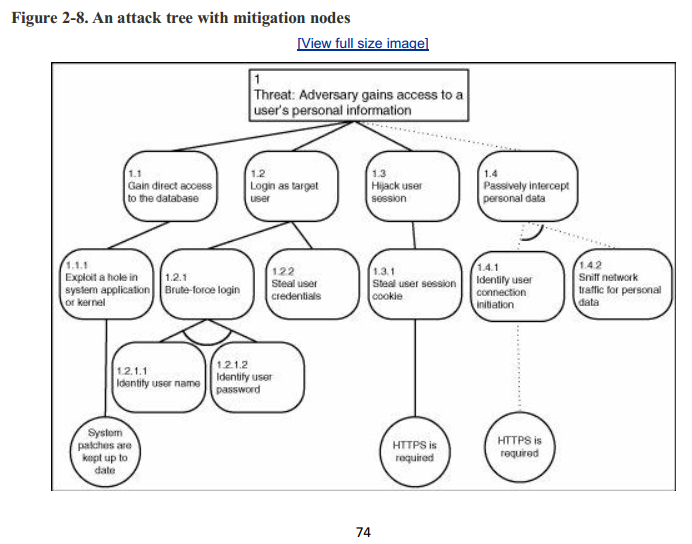
在此攻击树中添加了三个缓解节点,以帮助你认识到这些向量与未缓解的分支相比,不太可能成为攻击的途径。在一个缓解节点中使用的虚线是一种将分支标识为不太可能的攻击向量的简写方法。它不会移除分支,但会鼓励你将注意力转移到其他地方。
关于威胁减轻的最后一点注意事项:你不希望过早地去寻找它。识别缓解因素是有用的,因为它可以防止您追求一个不太可能的攻击向量。但是,你不希望陷入一种错误的安全感,从而错过一个可能的分支。因此,请仔细考虑缓解措施,并确保在将其添加到攻击树之前执行一些验证。
对寻找的结果进行文档记录
现在调查工作已经完成,你需要记录所发现的内容。在文档阶段,你将回顾在前一阶段发现的威胁,并以正式的方式呈现它们。对于你发现的每个威胁,你需要提供一个简短的总结,以及消除威胁的任何建议。要了解这个过程是如何工作的,请使用示例攻击树中的“蛮力登录”威胁(节点1.2.1)。这种威胁允许攻击者使用另一个用户的凭证登录。你的威胁总结文档将类似于表2-1。
| 威胁 | 蛮力登陆 |
|---|---|
| 受影响的组件 | Web应用的登录组件 |
| 描述 | 客户端可以使用登录,通过反复地连接和尝试登陆攻击用户名和密码。这个威胁会因为应用会对不合法的用户名和密码返回不同地错误消息,使得用户名更容易被确认而增加。 |
| 造成结果 | 不可信的客户端可以得到用户的用户名,然后读取或者修改他们的敏感信息。 |
| 减轻危害的策略 | 使错误消息模糊,以至于攻击者不知道什么样的用户名和密码是不合法的。在用户账户多次登陆失败后锁定。(3-5次尝试比较适合) |
关于蛮力登录威胁的所有信息都整齐地总结在一个表中。在本阶段的下一部分,您将扩展此表,以包括关于威胁风险的一些附加信息。
风险评级
与本章中的示例相比,实际应用程序在设计和实现方面通常要大得多,也更复杂。增加的大小和复杂性在各种用户类中创建了广泛的攻击向量。因此,你通常可以列出一长串的潜在威胁和可能的建议,以帮助减轻这些威胁。在一个完美的世界中,设计师可以系统地着手解决每一个威胁和潜在问题,必要时关闭每一个攻击向量。然而,某些业务现实可能不允许减少每个已确定的向量,而且几乎肯定不可能同时减少所有向量。显然,在担心那些不那么重要的风险之前,我们需要对一些更严重的风险进行优先排序。通过分配威胁严重程度评级,你可以根据每个未发现的威胁对应用程序和相关系统的安全性造成的风险对其进行排序。然后可以将此评级用作开发人员的指导方针,以帮助确定优先考虑哪些问题 。
你可以选择以多种不同的方式对威胁进行评级。最重要的是,你要考虑到威胁的暴露程度(利用的难易程度和载体的可用性)和在成功利用过程中所造成的伤害。除此之外,你可能希望添加与你的环境和业务流程更相关的组件。为了本章的威胁建模目的,使用了微软开发的恐惧评级系统。没有一个模型是完美的,但是这个模型在普遍接受的威胁特性之间提供了一个相当好的平衡。这些特点简述如下:
- 潜在损伤。如果威胁被成功利用,会有什么后果?
- 再现性。再现问题中的攻击有多容易?
- 可利用程度。实施攻击的难度是多少?
- 受影响的用户。如果攻击已经成功实施,有哪些用户会被影响,以及这些用户有多重要?
- 发现的难度。发现这个漏洞难度有多大?
每个类别都可以从1-10打分,1最低,10最高。 类别得分之和除以5作为整体威胁等级。3级或以下可视为低优先级威胁,4至7级为中等优先级威胁,8级或以上为高优先级威胁。
注
风险评级模型在给实现和操作漏洞上打分也非常有用。事实上,你可以使用风险评级模型作为你在整个过程中的审查通用评级系统。
风险评级系统的好处之一是,它提供了一系列的细节,你可以在向业务决策者展示结果时使用。你可以给他们一个简明的威胁评估,只包括总的威胁等级和它所属的类别。你还可以提供更详细的信息,比如五个威胁类别的个人得分。你甚至可以给他们一份完整的报告,包括模型文档和你如何得到每个类别的分数的解释。不管你的选择是什么,在向客户或高级管理人员做演示时,最好在每个细节级别都有可用的信息。
表2-2是一个对蛮力登录威胁的一个风险评级:
| 威胁 | 蛮力登录 |
|---|---|
| 受影响的组件 | Web应用的登录组件 |
| 描述 | 客户端可以使用蛮力登录,通过反复地连接和尝试登陆攻击用户名和密码。这个威胁会因为应用会对不合法的用户名和密码返回不同地错误消息,使得用户名更容易被确认而增加。 |
| 造成结果 | 不可信的客户端可以得到用户的用户名,然后读取或者修改他们的敏感信息。 |
| 减轻危害的策略 | 使错误消息模糊,以至于攻击者不知道什么样的用户名和密码是不合法的。在用户账户多次登陆失败后锁定。(3-5次尝试比较适合) |
| 风险 | 潜在损伤: 6,再现性: 8 |
| 可利用性: 4, 受影响的用户: 5 | |
| 可发现性:8 | |
| 总:6.2 |
自动威胁模型文档
正如你所看到的,在威胁建模过程(包括文本和图表)中涉及到相当多的文档。幸运的是,Frank Swiderski(前面提到的威胁建模的合著者)开发了一个工具来帮助创建各种威胁建模文档。它可以在http://msdn.microsoft.com/security/securecode/threatmodeling/上免费下载。该工具可以轻松地创建dfd、用例、威胁摘要、资源摘要、实现假设和您将需要的许多其他文档。此外,文档被组织成易于导航和维护的树结构。该工具可以使用可扩展样式表语言转换(Extensible Stylesheet Language transformation, XSLT)处理将所有文档输出为HTML或您选择的其他输出形式。强烈建议你熟悉这个用于威胁建模文档的工具。
确定实施审查的优先次序
现在你已经完成了威胁总结并对其进行了评分,你终于可以将注意力转移到构建实现审查上了。在开发威胁模型时,你应该根据各种因素(包括模块、对象和功能)分解应用程序。这些划分应该反映在每个单独威胁摘要的受影响组件条目中。下一步是在适当的分解级别创建组件列表;确切地说,什么级别是由应用程序的大小、审阅人员的数量、可用的审阅时间以及类似的因素决定的。但是,通常最好从抽象的高层开始,因此只需要考虑几个组件。除了组件名称之外,你还需要在列表中另一列列出与每个组件相关联的风险得分。
有了这个组件列表之后,你只需确定威胁摘要属于哪个组件,并将该摘要的风险得分添加到相关组件。在合计了汇总列表之后,你将获得与每个组件相关的风险评分。通常,你希望以最高分的部分开始你的评估,并继续从最高分到最低分的过程。由于时间、预算或其他限制,你可能还需要消除一些组件。所以最好从得分最低的部分开始剔除。你可以将此评分过程应用于下一级别的分解,在你拥有此组件列表之后,你只需确定威胁摘要属于哪个组件,并将该摘要的风险评分添加到相关组件即可。在合计了汇总列表之后,你将获得与每个组件相关的风险评分。通常,你希望以最高分的部分开始您的评估,并继续从最高分到最低分的过程。由于时间、预算或其他限制,你可能还需要消除一些组件。所以最好从得分最低的部分开始剔除。你可以将这个评分过程应用到大型应用程序的下一层分解;尽管这已经开始进入实施审查过程,这在第4章 “申请审查程序” 中会详述。
使用记分表可以让你更容易地对评审进行优先排序,特别是对于初学者来说。然而,这并不一定是完成工作的最佳方式。一个有经验的审核员通常能够根据他们对类似应用程序的理解对审查进行优先排序。理想情况下,这应该与威胁汇总得分一致,但有时情况并非如此。因此,将威胁总结考虑进去是很重要的,但当你有理由遵循更好的计划时,不要坚持使用它们。
6.2.5 总结
本章探讨了应用程序设计审查的基本要素。你已经了解了安全性需要成为应用程序设计中的基本考虑因素,并了解了设计过程中的决策如何极大地影响应用程序的安全性。你同样也了解了一些用于理解应用程序设计的安全性和潜在漏洞的工具。
重要的是,不要将设计审查过程视为一个孤立的组件。设计评审的结果应该自然地进展到在第4章讨论的实现审查过程中。
