flex lexer分析
flex会根据你定义的正则表达式匹配到相应字段,然后根据你定义的函数进行操作,返回相应的token。
为了了解flex如何work的,我们新建一个空的flex规则文件null.flex:
1 | %% |
然后运行命令flex null.flex生成lex.yy.c文件。
接下来逐行分析它的code:
首先是一些flex的版本相关的宏:
1 |
然后将一些type define成自己的格式:
1 |
|
然后定义EOF的宏:
1 |
将signed char安全转换为unsigned int的宏YY_SC_TO_UI:
1 |
start condition中用的BEGIN():
1 |
在后面的代码可以看出,这些start condition定义的关键词都被定义成了宏,比如我们有两个start condition COMMENT和STRING:
1 |
这时BEGIN(COMMENT)就等价于:
1 | (yy_start) = 1 + 2 * COMMENT |
之后就可以得到相应的YY_STATE:
1 |
略去其他不重要的宏,接下来看两个FILE指针yyin和yyout,可以看出yyin指向了stdin,yyout指向了stdout,分别对应了标准输入输出流:
1 | extern FILE *yyin, *yyout; |
接下来的代码就可以看出,flex的lexer是使用自顶向下的表驱动预测分析法来实现匹配的,关于这里面的预测分析,LL(1)文法等定义见编译原理的相关教材。
首先要实现表驱动预测分析,就要定义读入text的方法,理论上是一个个character读入,但为了效率起见,flex将它们批量读取存入了buffer中:
1 |
这里就要吐槽一下它的缩进了,简直惨不忍睹。如果你觉得这种读取方法很复杂的话,可以rewrite自己的YY_INPUT:
1 |
这段代码引自参考文献[1]。
为什么说它用的是表驱动法呢?从它在静态区cache了一些预测分析表的常量:
1 | static yyconst flex_int16_t yy_accept[6] = {...}; |
以及定义了将缓冲区变量压栈和出栈的一系列操作:
1 | void yypush_buffer_state (YY_BUFFER_STATE new_buffer ) |
再对比下自顶向下表驱动法的算法结构:

就一目了然了。
接下来就来看这个算法flex具体是如何实现的,它过程就在于yylex()这个函数,大致的框架如下:
1 |
|
这里的do_action中,yy_act只有0和1两种情况,即读到非EOF的直接accept,读到EOF转case 0。因为这是一个空的规则文件,假如我们用带有规则的xxx.flex生成code,这些规则中的正则表达式匹配方法会表现到静态区中cache的预测分析表中,匹配到的action会体现在这个switch-case语句中。
为了验证以上的说明,我们定义一个用来匹配能够解释为十进制数字符串的规则,放到文件test.flex:
1 | WHITE " "|\t|\f|\r|\v |
对应的DFA图如下:
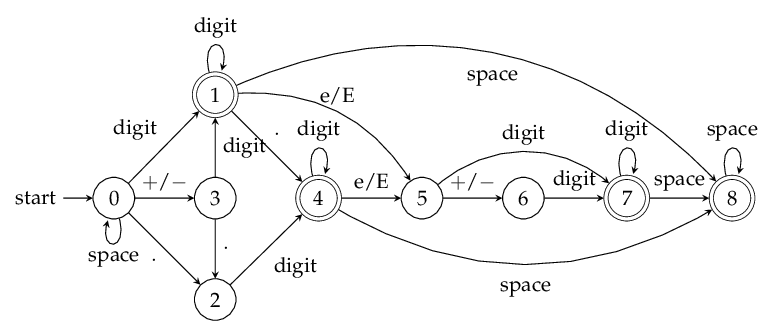
这个例子来自参考文献[1].
flex为了减少内存开销,对原来的状态表进行了压缩,因此在空规则生成的文件中,我们能看到很多个静态区常量(见上面),为了看到原本的状态表,我们使用 -Cf进行编译:flex -Cf test.flex ,然后可以看到:
1 | static yyconst flex_int16_t yy_nxt[][128] = {...}; |
其中flex_int16_t yy_nxt[][128]就是原来的状态表。在yylex()中,匹配的过程是这么写的:
1 | yy_match: |
现在我们只要照着它稍微修改一下,就能得到一个判断字符串是否能作为数字的程序了:
1 |
|
这里只需要判断新的current state是否大于0.没用必要查询是否accept(因为match时小于0直接跳出循环,说明匹配失败)。
对于压缩版本的,也可以有如下的对应。
yylex():
1 | yy_match: |
valid_number程序:
1 |
|
这里需要判断current state是否能被accept(即返回1),当然根据while循环条件也可以。
References:
[1].Flex技巧总结 && [LeetCode]Valid Number题解 https://blog.finaltheory.me/research/Flex-Tricks.html
