glibc malloc 源码分析
linux给了我们两种类型的系统调用来申请动态内存,分别是brk()和mmap(),malloc()仅仅是在这二者之上做了一些其他的事情而已,这里从源代码来剖析一下glibc malloc都做了什么。源代码是glibc v2.32版本。
chunk
‘chunk’指的就是malloc分配内存的最小单元,我们来看下它的数据结构:
1 | /* |
首先INTERNAL_SIZE_T其实就是无符号整数size_t:x86-64 linux下,32位操作系统为4字节32位,64位操作系统为64位8字节,用下面的这个宏定义:
1 |
这里面的4根指针注释上都强调了只有在free了后才使用,因此使用中的chunk是长这样的:
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
这里注意,mchunk_size最后面的3个bit是用来表示这个chunk的一些信息的,意义如下:
- A表示
NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。 - M表示
IS_MAPPED,记录当前chunk是否由mmap分配的,1表示是,0表示不是。 - P表示
PREV_INUSE,记录物理上相邻的前一个chunk是否正在使用,1表示正在使用,0表示没有。
接下来就是一些chunk的宏函数:
1 |
|
其中:
chunk2mem(p):偏移2*SIZE_SZ到用户真正使用的数据区MIN_CHUNK_SIZE:chunk的最小size。在CTF wiki的引用里面MIN_CHUNK_SIZE的定义是:1
这里
offsetof()函数返回的是一个size_t,大小为结构成员相对于结构开头的偏移量,在64位操作系统下,MIN_CHUNK_SIZE是32,32位操作系统下是16。MINSIZE:申请最小的堆内存大小,展开后和MIN_CHUNK_SIZE一样。(虽然是个无关紧要的细节,但我没看懂为什么要定义相同的MIN_CHUNK_SIZE和MINSIZE)
检查对齐的宏:
1 | /* Check if m has acceptable alignment */ |
这里可以看出,申请内存大小必须是2*SIZE_SZ的整数倍,否则也会给你对齐到整数倍。
然后是把malloc请求的size转换为对应chunk的size宏和对request size做检查的宏:
1 | /* pad request bytes into a usable size -- internal version */ |
接下来是对chunk做一些操作的宏,从命名和定义就可以看出具体用途:
1 | /* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ |
Bin
前面也说了,chunk是用户通过malloc申请内存的最小单元,glibc malloc不会在一个chunk free了以后马上将内存还给操作系统,而是创建了一些数据结构来接管他们,以节省再次申请时的时间,由于时间空间局部性的存在,这种设计一般来说是能起作用的(当然对于生命周期很长的程序这样的设计可能导致一大堆内存释放不掉)。在内部为了管理这些free chunk,glibc使用了一种叫bins的结构:
1 |
|
这里就能看出来,bins是一个chunk指针组成的数组,而前面chunk的数据结构定义中也有指向前一个free chunk和后一个free chunk的指针(如果这个chunk也是free的话),也就是说,bins实际上就是一个管理free chunk的链表数组。在bins中,如果两个free chunk是物理相邻的,两个chunk就会合并以减少内存碎片,相似地,如果在bins里找不到malloc要的size大小的chunk,那么就会从大chunk中分割出一个符合size要求的chunk来,这个步骤后面的代码会看到。
bins又细分为fastbin,smallbin,largebin和unsortedbin,free chunk会根据一些规则被分到这4个组里。
Fast Bin
首先,小size的chunk在free后如果物理相邻就会被合并,但很多程序常常会申请和释放小内存块,要是每次malloc或者free小块都会进行合并和分割就会导致程序变慢,为了照顾着一些很常用的小块内存,fast bins就出现了:
1 | typedef struct malloc_chunk *mfastbinptr; |
NFASTBINS展开以后是10,而根据fastbin_index的定义(这个定义中的-2显然受到了MIN_CHUNK_SIZE的约束),0和1的index不存在,因此fastbin最多cache 8个chunk,根据这个宏可以推出每个index对应的chunk size大小:
| index | 32位系统(SIZE_SZ=4) | 64位系统(SIZE_SZ=8) |
|---|---|---|
| 0 | 不存在 | 不存在 |
| 1 | 不存在 | 不存在 |
| 2 | 16 | 32 |
| 3 | 24 | 48 |
| 4 | 32 | 64 |
| 5 | 40 | 80 |
| 6 | 48 | 96 |
| 7 | 56 | 112 |
| 8 | 64 | 128 |
| 9 | 72 | 144 |
注意,在fast bins中的free chunk是LIFO的,使用单向链表实现,fast bins能fast也是基于时间空间局部性。在malloc申请一个chunk时,首先就会在fast bins中查找有没有适合的size,如果没用才会进行后面的操作:
1 | /* Set if the fastbin chunks contain recently inserted free blocks. */ |
BTW,fast bins中的chunk会被标记为使用中,即链表中chunk的PREV_INUSE都会被设置为1,为了防止被合并。
Small bin
顾名思义,small bins就是包含着小size chunk的bins:
1 |
从源码中可以看出,一个chunk是small还是large,是由宏MIN_LARGE_SIZE决定的,这个size在64位操作系统上是1024,在32位系统上是512,小于它的被定义为small chunk,大于等于的是large chunk。
而根据smallbin_index(sz)的indexing规则,32位系统下(SMALLBIN_WIDTH != 16)为sz/8,64位下为sz/16,在已知sz必须和2 * SIZE_SZ(64位操作系统为16,32位操作系统为8)对齐的情况下,那么我们就能反推出small chunk总共的index数量为1024/16=64,正好和NSMALLBINS对上了!
然后我们就可以得到不同small bin的index下,每个size的chunk的一一对应关系,注意MIN_CHUNK_SIZE规定了最小的size,因此index是1和0的情况是不存在的,所以实际情况上,small bins有62个index!
| index | 32位系统(SIZE_SZ=4) | 64位系统(SIZE_SZ=8) |
|---|---|---|
| 2 | 16 | 32 |
| 3 | 24 | 48 |
| 4 | 32 | 64 |
| x | 24x | 28x |
| 63 | 504 | 1008 |
fast bin是和small bin的范围有重合的,实际上,fast bins就是small bins的cache。
Large Bin
搞懂了small bins,large bins就很简单了,前面说过,比MIN_LARGE_SIZE大的chunk都称为large bins,它们是如何indexing的就看源代码怎么定义的了:
1 |
|
看一下这个嵌套三元表达式的宏就知道,large bins一共分为了6组,每组的index个数可以从移位算符得出,算一算就可以知道它们一一对应到表里,glibc内存管理ptmalloc源码分析里有完整的数据,这里给出CTF wiki的比较简短的总结:
| 组号 | index个数 | 公差 |
|---|---|---|
| 1 | 6 | 64 |
| 2 | 16 | 512 |
| 3 | 8 | 4096 |
| 4 | 4 | 32768 |
| 5 | 2 | 262144 |
| 6 | 1 | 不限制 |
Unsorted Bin
源码定义如下:
1 | /* The otherwise unindexable 1-bin is used to hold unsorted chunks. */ |
可见unsorted bin定义在了bins的第一个index下,因此unsorted bin只是一个链表。
Top Chunk
glibc对top chunk定义和描述如下:
1 | /* |
根据注释描述,所谓的top chunk就是位于可用堆内存地址最高位的chunk,它不属于任何bin,只有当没有chunk可用时它才会向系统去申请扩展heap的可用区域。为防止被合并,top chunk的prev_inuse始终为1。初始情况时,unsorted chunks用作top chunk。
现在总结一下,宏NBINS告诉我们bins一共有108个入口,small bins有62个,large bins一共有63个,加起来125个bin,根据bin的indexing宏bin_at的定义,bin[0]和bin[127]是不存在的,因此bin[1]就是top chunk,也是unsorted bin,加起来总共126个。
BTW,bins的定义是:
1 | mchunkptr bins[NBINS * 2 - 2]; |
也就是实际size有NBINS * 2 - 2一共254个mchunkptr,而chunk实例的是6个mchunkptr的大小,这怎么存的下呢?但我们注意到,bins中的chunk是头节点,那么chunk中的mchunk_prev_size和mchunk_size是没有意义的!而fd_nextsize和bk_nextsize只有large chunk才会用到,那么出于节省内存的想法,我们只需要2个mchunkptr,总共需要的就是126*2=254个mchunkptr的大小,正好对上了!
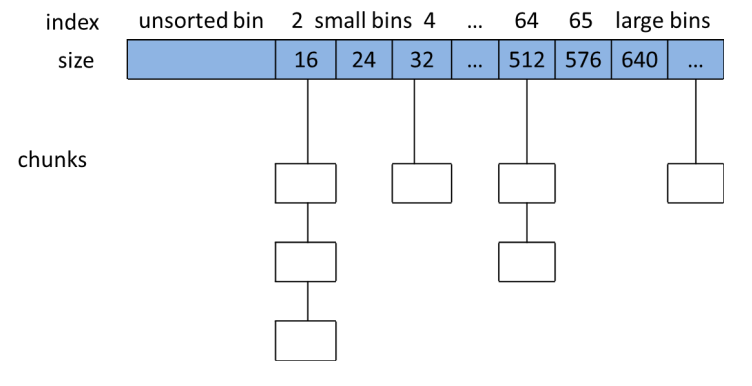
总之,glibc的malloc使用的内存管理方法就是链表数组的内存池,和gnu C++远古版本std allocator是相同的思想,因此在后面版本的gnu C++里面默认allocator都是封装malloc,如果看了侯捷的STL源码剖析,别被书里推崇无比的内存池allocator误导了。
其他核心结构
malloc_state
定义如下:
1 | struct malloc_state |
这里就可以看到,前面所说的bins是malloc_state的一部分,因此一个malloc_state的实例就是一个分配区域,下面一一说明这些变量:
flags是一些标志位,它的用途从后面的宏定义就可以看出来:
1 | /* |
这里就是用flags的第2位来判断MORECORE是否返回了连续的虚拟地址空间,0为是,1为否。实际上MORECORE就是系统调用sbrk(),只是经过了重重包装:
1 |
|
have_fastchunk用来表示这个分配区域是否有fast chunk。以前版本的glibc malloc是用flags的第1位来判断是否有fast chunk的,定义宏的方法和contiguous是一样的,但我看的这个版本是在malloc_state定义了一个have_fastchunk来判断,感觉新的版本有点浪费内存资源了。
fastbinsY,前面已经说过了,存储fast chunk链表指针的数组。
top,指向bins top chunk的指针。
last_remainder,指向chunk的指针, 分配区上次分配 small chunk 时,从一个 chunk 中分 裂出一个 small chunk 返回给用户, 分裂后的剩余部分形成一个 chunk,last_remainder 就是 指向的这个 chunk 。
bins:前面说过了,存储chunk的链表指针数组,分为unsorted bin,fast bin,small bin, large bin,bin[0]不存在,bin[1]是unsorted bin。
binmap:一个int数组,关于它的用途,可以看下面部分的代码:
1 | /* Conservatively use 32 bits per map word, even if on 64bit system */ |
这里可以看出BINMAPSIZE的值是128/32=4,我们知道int是32位,那么binmap实际上就是一个128位的buffer,这些宏就是在定义每一位对应每一个bins的映射关系,ptmalloc就使用这些位来标记对应bin中是否有free chunk。
next:一根指向下一个分配区的指针。
next_free:一根指向下一个free分配区的指针。
system_mem:记录当前分配去已经分配的内存大小。
max_system_mem:记录当前分配去最大能分配的内存大小。
malloc_par
定义如下:
1 | struct malloc_par |
各个变量的意义如下(摘自ptmalloc源码剖析):
trim_threshold字段表示收缩阈值,默认为 128KB,当每个分配区的 top chunk 大小大于 这个阈值时,在一定的条件下,调用 free 时会收缩内存,减小 top chunk 的大小。由于 mmap 分配阈值的动态调整,在 free 时可能将收缩阈值修改为 mmap 分配阈值的 2 倍,在 64 位系 统上, mmap 分配阈值最大值为 32MB,所以收缩阈值的最大值为 64MB,在 32 位系统上, mmap 分配阈值最大值为 512KB,所以收缩阈值的最大值为 1MB。 收缩阈值可以通过函数 mallopt()进行设置。
top_pad 字段表示在分配内存时是否添加额外的 pad,默认该字段为 0。 mmap_threshold 字段表示 mmap 分配阈值,默认值为 128KB,在 32 位系统上最大值为 512KB, 64 位系统上的最大值为 32MB,由于默认开启 mmap 分配阈值动态调整,该字段的 值会动态修改,但不会超过最大值。
arena_test 和arena_max 用于 PER_THREAD 优化,在 32 位系统上 arena_test默认值为 2, 64 位系统上的默认值为 8, 当每个进程的分配区数量小于等于 arena_test 时,不会重用已有 的分配区。为了限制分配区的总数,用 arena_max 来保存分配区的最大数量,当系统中的分 配区数量达到 arena_max,就不会再创建新的分配区,只会重用已有的分配区。 这两个字段 都可以使用 mallopt()函数设置。
n_mmaps 字段表示当前进程使用 mmap()函数分配的内存块的个数。 n_mmaps_max 字段表示进程使用 mmap()函数分配的内存块的最大数量,默认值为 65536,可以使用 mallopt()函数修改。 max_n_mmaps字段表示当前进程使用 mmap()函数分配的内存块的数量的最大值,有关 系 n_mmaps <= max_n_mmaps 成立。 这个字段是由于 mstats()函数输出统计需要这个字段。 no_dyn_threshold 字段表示是否开启 mmap 分配阈值动态调整机制,默认值为 0,也就 是默认开启mmap 分配阈值动态调整机制。 pagesize 字段表示系统的页大小,默认为 4KB。 mmapped_mem 和 max_mmapped_mem 都用于统计mmap 分配的内存大小,一般情况 下两个字段的值相等, max_mmapped_mem用于mstats()函数。 max_total_mem 字段在单线程情况下用于统计进程分配的内存总数。 sbrk_base字段表示堆的起始地址。
References:
[1]. https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/heap_structure-zh
[2].glibc内存管理ptmalloc源码分析
