简易内核实现笔记(一) ——开启操作系统前的准备
BIOS
在计算机电源打开的一瞬间,x86架构的CPU处于实模式下,所谓的实模式就是8086CPU运行的模式,x86家族的CPU为了做到向下兼容,全部默认开机时运行在8086的模式下,在实模式中,所有的地址都是物理地址,寄存器大小都是16位,寻址采用20位地址线,由段地址左移4位+偏移地址实现。
在实模式背景下,第一行代码的位置是0xf000:0xfff0,也就是0xffff0,这一行代码的指令是jmp f000:e05b,这个跳转的地址就是BIOS的第一行代码地址,随后BIOS就会进行硬件自检,在没有问题后就会执行最后一行代码jmp 0x7c00跳转到主引导程序MBR处。
MBR
MBR占512字节,正好是一个硬盘扇区的大小,在这512字节的程序中,MBR的任务就是把加载器载入内存中执行:
1 | ;主引导程序 |
可以看到MBR的代码分为两部分,第一个部分就是在窗口打印”1 MBR”这几个字符,这是通过向段起始0xb800处的内存写入字符实现的。在实模式下,这个地址就是显存的位置。第二部分就是写入loader,也就是函数rd_disk_m_16,在这个函数里,cx寄存器储存的是要读的磁盘扇区个数。相关的宏定义如下:
宏LOADER_START_SECTOR就是0x2,表示我们要向磁盘第三个扇区(第一个是0x0)读loader,LOADER_BASE_ADDR就是loader被写入的地址0x900。
在加载完loader之后,MBR的使命就结束了,最后一条命令jmpLOADER_BASE_ADDR+0x300就是跳转到loader的第一条命令去执行loader。
Loader
我们的loader就负责做四个事情:
- 加载全局描述符表
- 进入保护模式
- 创建页表,展开虚拟地址空间
- 加载操作系统内核
保护模式
所谓的保护模式就是可以寻址32位(4GB)的模式,而’保护’二字指的就是在这个模式下CPU为程序执行提供了一些内存的保护措施,这个措施就是通过全局描述符表来实现的。为了开启保护模式,我们要做3件事:
- 加载全局描述符表
- 打开A20 Gate
- 修改控制寄存器CR0第一位为1
全局描述符表
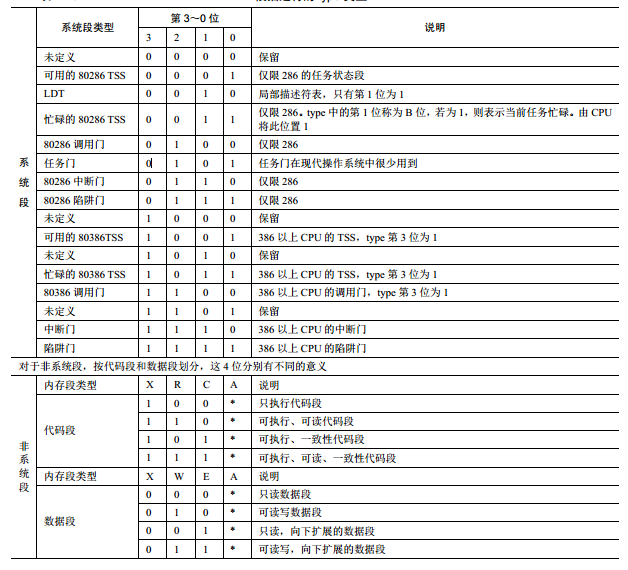
全局描述符表就是一个表,存储着段描述符,所谓的描述符就是关于内存段的一些信息,CPU会根据这些信息做出相应的措施,所谓的全局就是指这个表不是局部的。一个描述符占了64位8字节,每位的意义如下:
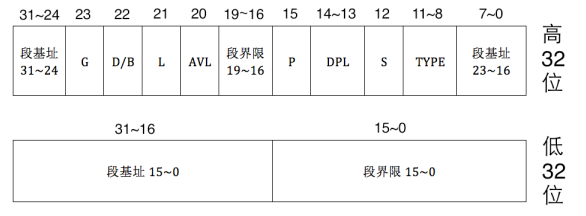
由于一些向下兼容的原因,一些东西是不连续的,但不妨碍我们理解:
- 段界限:一个段的最大大小是20位,如果索引超过段界限CPU会触发异常。
- G:段界限的粒度,如果G为0就代表粒度是1位,对应到段界限就是20位1MB。G为1就代表粒度为4KB,对应到段界限就是4GB,因此实际的段界限大小等=粒度大小*段界限-1
- 段基址:顾名思义,不用说了
- D/B:一个用来兼容80286保护模式的位,表示有效地址和操作数的位数。D为0表示16位,D为1表示32位(所以对我们不用80286的就没什么用)
- L:为1表示64位代码段,0表示32位
- AVL:available字段,这个available是对于用户来说的,不是硬件,所以是可以随便用的
- P:用于指示段是否存在于内存中,用到这个段时如果它不存在,就会触发CPU的异常,然后跳转到异常处理程序中把它加载到内存中。
- DPL:表示特权级,特权级一共4级,从高到低为0,1,2,3。
- S:为1表示系统段,0表示非系统段
- type:段的类型,这三位对于系统段和非系统段有不同的定义:
A20 Gate
实模式能够寻址的空间是1MB 20位,要进入保护模式的32位寻址,就要去除20位寻址的限制,这个限制被称为A20 Gate,打开A20 Gate的方法就是将端口0x92的第一个位置写为1:
1 | in al,0x92 |
而进入保护模式的方法就是将控制寄存器CR0的第0位写为1:
1 | mov eax, cr0 |
因此,进入保护模式的代码如下:
1 | ;----------------- 准备进入保护模式 ------------------- |
虚拟地址空间
在进入保护模式之后,我们所访问的32位地址仍然是物理地址,虚拟地址为我们提供了一层抽象,使得每个进程都可以在32位地址空间中运行,我们只需要通过页表将它们映射到物理地址即可,这样写程序就不用再自己去管地址从哪里开始了。
页表
页表是虚拟地址与物理地址的映射关系,由于将来每个操作系统下的进程,包括操作系统自己都是在32位虚拟地址空间中运行的,因此每个进程都需要有自己的页表,我们将物理地址分页,每个页占有4kB的大小,一个页表项就占32位4字节,检索4GB的虚拟内存空间总共需要1M个页表,在内存中占4MB,这个大小显然是无法接受的,因此我们再创建一个页表的页表,也就是页目录表,一个页目录项也是32位4字节,因此一个页目录项也可以索引4kB的空间,那么检索4GB的虚拟地址空间只需要4GB/4kB/4kB=1024个页目录,只需要4096个字节就可以了,这样的开销就可以接受。
对于1024个页目录,我们需要10位地址来进行索引,这10位地址就是虚拟地址中的高10位,我们将这10位地址4就是对应页表的偏移地址,再加上页目录表的起始地址就得到了对应页表所在的物理地址,一个页表中有1024个页,因此检索它也需要10位地址,这10位地址就是虚拟地址中的中间10位,我们用这中间10位地址4就得到了所在页的偏移地址,加上前面得到的页表物理地址就得到了对应页所在物理地址,这个页中存储的就是真实物理地址的偏移量,再加上最低12位虚拟地址就得到了对应的真实物理地址了。
因为每个页表项都是4字节,因此它们的值里面低12位全是0,因此为了避免浪费就要往里面加一些关于页表的安全信息:
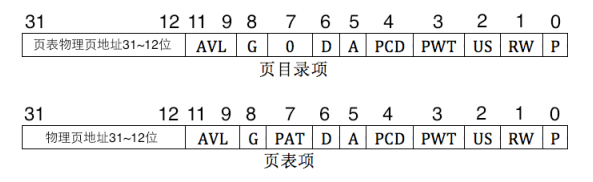
其中:
- P:该页存在于物理地址中
- R/W:读写权限,0表示只读,1表示可读可写
- US:普通用户/超级用户位,为1表示在普通用户级,普通用户在特权级3
- PWT:通写位,1表示处于通写模式,表示改该页是高速缓存
- PCD:打开使用高速缓存
- A:访问位,如果CPU访问过该页,就会把它置为1,之后的操作系统我们会将它置为0,通过count置为1的次数就能判断它是否常常被使用,是就将这个页存入缓存中
- D:脏页位,CPU对一个页进行写操作时,就会把这个位置为1,仅对页表项有效
- G:global位,若为global,那么这个页表就会一直在高速缓存TLB中保存
- AVL:软件的可用为,CPU不会管,怎么用就是软件定义的了
对页表的初始化我们要有一个约定,也就是4GB的虚拟地址空间中,高1GB是只有操作系统内核才能访问的区域,因此在初始化页表时我们要将内核区的页表和普通页表分开,并且为了减小开销在未来将所有进程的内核页表通用,所以完整的loader代码如下:
1 | %include "boot.inc" |
注意,在内核页表中,我们仍置US位为U,是因为内核的加载程序是运行在用户特权下的。由于我们目前只需要1MB的物理内存,每个页能映射4kB,因此只需要创建256个普通页表项,普通页表目录也只需要一个,并且这1MB的内存中,虚拟地址就等于物理地址。另外,第一个内核页表目录也指向256个普通页表项,因为我们需要让内核在这1MB的物理内存下被加载运行,之后的那1GB内核虚拟内存的页表和页表目录创建时就把P位置为0,表示他们不存在于内存中。
在加载完页表之后,我们就可以把控制寄存器CR0的第31位置为1,表示让CPU开启虚拟寻址模式,然后重新将全局描述符表加载到内核区域,再将内核加载到内核区的内存中就可以运行操作系统内核了。
载入内核程序
在载入内核之前,首先我们要了解ELF文件格式,ELF的E和L就是executable and linkable的缩写,一个ELF文件在链接或者执行视图中可以分段(segment)或者分节(section):
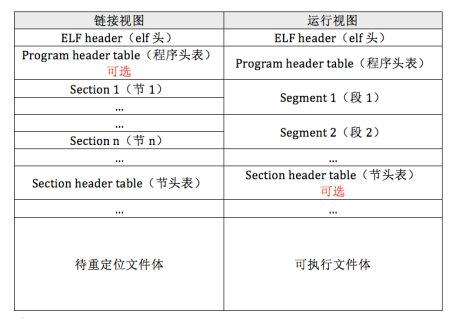
elf的header是一个数据结构,用来记录这个ELF文件的信息:
1 | /* 32位elf头 */ |
其中,e_indent[16]功能如下:
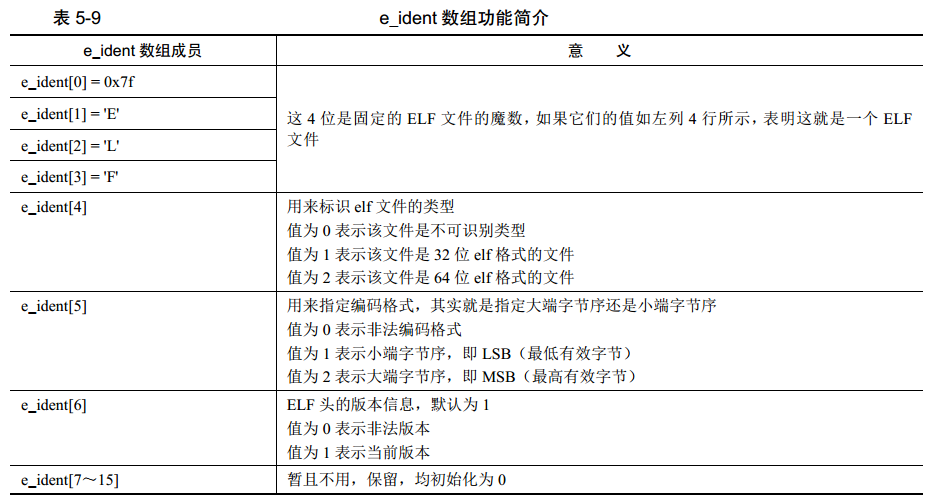
e_type占2字节,表示elf目标文件类型,一共有下面几种:
| elf目标文件类型 | 取值 | 意义 |
|---|---|---|
| ET_NONE | 0 | 未知目标文件格式 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 动态共享目标文件 |
| ET_CORE | 4 | core文件,即程序崩溃时其内存映像的转储格式 |
| ET_LOPROC | 0xff00 | 特定处理器文件的扩展下边界 |
| ET_HIPROC | 0xffff | 特定处理器文件的扩展上边界 |
其余的字段意义如下:
| 字段 | 大小(字节) | 意义 |
|---|---|---|
| e_machine | 2 | 支持的硬件平台 |
| e_version | 4 | 表示版本信息 |
| e_entry | 4 | 操作系统运行该程序时,将控制权转交到的虚拟地址 |
| e_phoff | 4 | 程序头表在文件内的字节偏移量。如果没有程序头表,该值为0 |
| e_shoff | 4 | 节头表在文件内的字节偏移量。若没有节头表,该值为0 |
| e_flags | 4 | 与处理器相关的标志 |
| e_ehsize | 2 | 指明 elf header 的字节大小 |
| e_phentsize | 2 | 指明程序头表(program header table )中每个条目(entry)的字节大小 |
| e_phnum | 2 | 指明程序头表中条目的数量。实际上就是段的个数 |
| e_shentsize | 2 | 节头表中每个条目的字节大小,即每个用来描述节信息的数据结构的字节大小 |
| e_shnum | 2 | 指明节头表中条目的数量。实际上就是节的个数 |
| e_shstrndx | 2 | 指明 string name table 在节头表中的索引 index |
在加载程序中,我们需要做的就是将内核按照编译好的虚拟地址将各个段复制到对应的位置,然后jump到内核的运行入口(链接时可用指定)去开启内核,然后loader的生命历程就结束了。
附录
虚拟机bochs的安装与配置
这里使用2.6.2版本,下载地址: https://sourceforge.net/projects/bochs/files/bochs/2.6.2/
下载源代码文件之后解压进入目录,然后配置:
1 | ./configure \ |
然后make,如果报错说
1 | Makefile:179: recipe for target 'bochs' failed |
就再makefile里找到LIBS =,尾部加上-lpthread,注意这里不要再configure,否则makefile会被覆盖,再make,make install就可以了
进入bochs的目录,然后配置文件bochsrc.disk:
1 | # Configuration file for Bochs |
然后运行bin/bximage,创建一个60M的虚拟硬盘,遇到选项全部回车,然后问size的时候填个60,然后把让你复制的这一行:ata0-master: type=disk, path="hd60M.img", mode=flat, cylinders=121, heads=16, spt=63复制到配置文件中,记得path改成绝对路径,bochs不认识相对路径
之后运行bochs就完事了